Nel definire la struttura e le relazioni fra le collezioni che costituiscono un database, è opportuno tenere in considerazione vari fattori.
Nei database tradizionali in fase di progettazione di un database e modellazione dei dati si punta a ridurre al minimo le ridondanze attraverso un processo di normalizzazione il quale consiste nello scomporre le tabelle e nel definire dei vincoli di integrità referenziale per assicurare che le relazioni tra le tabelle stesse siano sempre coerenti. Le tabelle presentano inoltre uno schema ben definito già in fase di progettazione.
Con la normalizzazione i dati vengono distribuiti in diverse tabelle e le informazioni non vengono ripetute. Così facendo, se dovessimo aggiornare dei dati, sarebbe sufficiente apportare delle modifiche ai record di una sola tabella.
Principi e parametri da valutare per definire lo schema di un documento
In MongoDB i documenti non devono per forza avere uno schema fisso e al momento non esistono dei sistemi per stabilire dei vincoli di integrità referenziale fra documenti.
Non è inoltre sempre necessario normalizzare i dati anzi, in molte occasioni, si tende a seguire il processo inverso di denormalizzazione incorporando tutti i dati in un unico documento. Ciò è favorito dalle proprietà dei documenti e dalla possibilità di avere dei campi di tipo array o documenti annidati. Così facendo, accade che invece di mantenere dei riferimenti ai documenti di altre collezioni, in alcuni casi troviamo dati ridondanti che vengono interamente copiati all’interno dei documenti. In questo modo possiamo leggere le informazioni più velocemente, in compenso avremo il problema di dover apportare delle modifiche in più documenti nel caso in cui i dati venissero aggiornati.
In MongoDB sarà quindi opportuno trovare un punto di equilibrio sapendo che la normalizzazione dei dati riduce le ridondanze e rende più agevoli le operazioni di scrittura e aggiornamento. Al contrario incorporando gli stessi dati in più documenti otterremo letture più veloci, ma sarà più complicato assicurare un aggiornamento dei dati corretto e coerente.
Per definire la struttura dei documenti è bene partire dal modo in cui le applicazioni useranno e mostreranno i dati tenendo quindi in considerazione il tipo di query e la frequenza con cui si effettuano determinate operazioni.
In MongoDB è possibile avere dei dati di tipo Array e annidare altri documenti, ma bisogna ricordare che ogni documento BSON può avere una dimensione massima di 16MB per evitare un eccessivo consumo di RAM o di banda durante la trasmissione dei dati.
È pertanto necessario tenere in considerazione quali sono le relazioni fra documenti e stabilire se è opportuno incorporare documenti interi, parte di essi o se semplicemnte includere un riferimento ad un documento esterno. Questa scelta dipende ovviamente dal tipo di query da effettuare e dalla frequenza con cui vengono effettuate le operazioni di lettura, scrittura e aggiornamento, ma anche dalla facilità di accedere alle informazioni in un documento di una collezione.
Tipi di relazioni
Avendo determinato il tipo di relazione fra i documenti, dovremo poi stabilire la cardinalità delle relazioni in base alla quale è possibile capire qual è il modo migliore per strutturare i documenti.
Le relazioni rientrano in una delle tre seguenti categorie:
- uno a uno (1:1)
- uno a molti (1:N)
- molti a molti (N:M)
Relazioni uno a uno
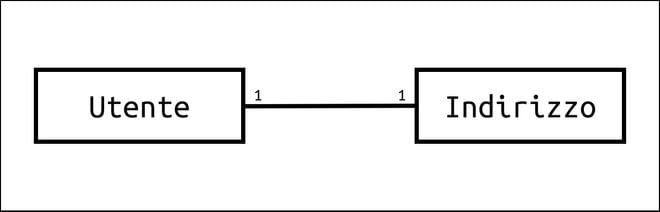
Le relazioni uno a uno coinvolgono due entità, nel caso di MongoDB due documenti. Per esempio possiamo immaginare di realizzare un’applicazione in cui decidiamo che ad ogni utente è associato un solo indirizzo di residenza e ad ogni indirizzo può corrispondere uno e un solo utente.
Le relazioni 1:1 sono costruite in due possibili modi in MongoDB. Il primo consiste nell’includere un documento che possiamo considerare secondario direttamente nel documento su cui effettuiamo la query. L’altro metodo consiste nell’inserire un riferimento nel documento secondario verso un documento che fa parte di un’altra collezione. Quest’ultimo approccio è simile a quello usato nei database tradizionali.
Partiamo dal primo metodo che in realtà abbiamo già incontrato in alcune delle precedenti lezioni. Consideriamo il caso del documento relativo ad un utente e quello in cui sono salvate le informazioni del suo indirizzo di residenza. Inizialmente supponiamo di avere due documenti indipendenti. Vedremo a breve come creare una relazione fra i due.
{
"_id": ObjectId("622b3140e991f738e3f0e9a8"),
"name": 'John Doe',
"email": 'john.doe@mail.tld',
"age": 44
}{
"_id": ObjectId("686b3160d211f419e3f0e9bb"),
"city": "Leeds",
"street": "114, Wellington St",
"postcode": "LS14LT"
}Seguendo il primo metodo, dovremo semplicemente aggiungere un campo al documento dell’utente per inserire il documento annidato relativo all’indirizzo.
{
"_id": ObjectId("622b3140e991f738e3f0e9a8"),
"name": 'John Doe',
"email": 'john.doe@mail.tld',
"age": 44,
"address": {
"city": "Leeds",
"street": "114, Wellington St",
"postcode": "LS14LT"
}
}Si tratta dello stesso documento che abbiamo già incontrato in altri esempi e permette di accedere all’indirizzo dell’utente ‘John Doe’ con una singola lettura senza dover interrogare una seconda collezione o unire documenti diversi. Questo approccio può essere utile nei casi in cui sia necessario ottenere le informazioni relative all’indirizzo ogni volta che si richiedono i dati di un utente. Inoltre trattandosi di un documento annidato con pochi campi, non si correrà il rischio di avere un documento di grandi dimensioni.
Il metodo alternativo è più simile alle tecniche usate nei database tradizionali. Consiste nel creare due collezioni separate, una per gli utenti e l’altra per gli indirizzi. Dovremo poi inserire un campo nel documento secondario per creare un collegamento con il documento primario.
{
"_id": ObjectId("622b3140e991f738e3f0e9a8"),
"name": 'John Doe',
"email": 'john.doe@mail.tld',
"age": 44
}{
"_id": ObjectId("686b3160d211f419e3f0e9bb"),
"user_id": ObjectId("622b3140e991f738e3f0e9a8"),
"city": "Leeds",
"street": "114, Wellington St",
"postcode": "LS14LT"
}Nell’esempio abbiamo inserito un campo ‘user_id’ nel documento che contiene le informazioni sull’indirizzo dell’utente. Tale campo contiene un valore uguale all’identificativo del documento dell’utente ‘John Doe’. In questo caso possiamo ottenere i dati completi di un utente in due modi. Possiamo usare l’operatore $lookup dell’Aggregation Framework che esegue un’operazione di LEFT JOIN, oppure possiamo effettuare due richieste separate gestendo la relazione fra documenti a livello dell’applicazione.
In MongoDB non esiste attualmente un metodo per garantire l’integrità delle relazioni fra documenti. Se un documento viene aggiornato, bisogna assicurarsi di apportare le modifiche necessarie per far in modo che le relazioni fra collezioni restino coerenti.
Relazioni uno a molti
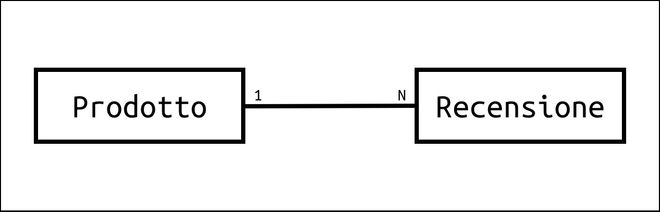
Le relazioni uno a molti (1:N) si riferiscono ai casi in cui a un documento sono associati molti altri.
Nell’immagine abbiamo un esempio di questa relazione in cui a ciascun prodotto sono associate diverse recensioni, ma ciascuna recensione si riferisce ad un solo prodotto.
Il primo approccio per modellare questo tipo di relazioni è attraverso un array di documenti annidati.
Abbiamo visto vari esempi di questo tipo nelle lezioni precedenti. Il più semplice riguarda i documenti della collezione ‘sample_restaurants.restaurants’ in cui abbiamo un campo ‘grades’ che è un array di documenti annidati.
{ _id: ObjectId("5eb3d668b31de5d588f4292a"),
address: {
building: '2780',
coord: [ -73.98241999999999, 40.579505 ],
street: 'Stillwell Avenue',
zipcode: '11224'
},
borough: 'Brooklyn',
cuisine: 'American',
grades: [
{ date: 2014-06-10T00:00:00.000Z, grade: 'A', score: 5 },
{ date: 2013-06-05T00:00:00.000Z, grade: 'A', score: 7 },
{ date: 2012-04-13T00:00:00.000Z, grade: 'A', score: 12 },
{ date: 2011-10-12T00:00:00.000Z, grade: 'A', score: 12 }
],
name: 'Riviera Caterer',
restaurant_id: '40356018' }In questo caso possiamo recuperare i punteggi direttamente con il resto delle informazioni di ciascun ristorante senza dover unire documenti di diverse collezioni o dover effettuare più richieste. Questo approccio è particolarmente efficace in questo caso specifico perché i documenti annidati contengono solo campi che fanno riferimento esclusivo a ciascun ristorante. Inoltre è piuttosto raro il caso in cui sia necessario aggiornarli.
Uno dei problemi con questo approccio si presenta nel caso in cui i documenti annidati dovessero aumentare in numero causando un incremento significativo delle dimensioni del documento. Se consideriamo la collezione ‘sample_airbnb.listingsAndReviews’ che abbiamo caricato su MongoDB Atlas nelle prime lezioni, ci accorgiamo che ogni alloggio presenta un gran numero di recensioni.
{ _id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
bed_type: 'Real Bed',
property_type: 'house',
review_scores: {
review_scores_accuracy: 9,
review_scores_cleanliness: 9,
review_scores_checkin: 10,
review_scores_communication: 10,
review_scores_location: 10,
review_scores_value: 9,
review_scores_rating: 89
},
reviews: [...]
}In questi casi possiamo usare uno dei pattern più comuni per definire lo schema di un documento, ovvero il Subset Pattern.
Invece di salvare tutte le recensioni nell’array del campo ‘reviews’ possiamo inserirne solo un certo numero. Per esempio, se le informazioni di ciascun alloggio sono mostrate in una pagina web che contiene un’anteprima delle ultime 5 recensioni, possiamo salvare solo le 5 recensioni più recenti nell’array ‘reviews’.
{ _id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
bed_type: 'Real Bed',
property_type: 'house',
reviews: [
{
"_id": "58663741",
"date": {
"$date": "2016-01-03T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "51483096",
"reviewer_name": "Cátia",
"comments": "..."
},
...
]
}Le restanti recensioni saranno invece salvate in una collezione separata. Ciascuna recensione dovrà contenere però un riferimento al documento che descrive l’alloggio a cui sono associate.
{
{
"_id": "62413197",
"date": {
"$date": "2016-02-14T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "40031996",
"reviewer_name": "Théo",
"comments": "..."
}
{...},
{...},
...
}In alternativa possiamo usare un approccio simile a quello dei database tradizionali. In questo caso dovremo rimuovere qualsiasi informazione relativa alle recensioni che saranno salvate in una collezione separata. Ogni recensione avrà anche un campo ‘listing_id’ per mantenere un riferimento al documento primario relativo a ciascuna proprietà.
{ _id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
bed_type: 'Real Bed',
property_type: 'house'
}{
{
"_id": "58663741",
"date": {
"$date": "2016-01-03T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "51483096",
"reviewer_name": "Cátia",
"comments": "..."
},
{
"_id": "62413197",
"date": {
"$date": "2016-02-14T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "40031996",
"reviewer_name": "Théo",
"comments": "..."
}
{...},
{...},
...
}Un altro tipo di approccio prevede di creare sempre 2 collezioni, una per gli alloggi che chiamiamo ‘listing’ e una per le recensioni che denominiamo ‘reviews’. In questo terzo metodo, nei documenti della prima collezione avremo un array ‘reviews’ che contiene solo degli identificativi relativi ai documenti conservati nella collezione ‘reviews’.
{ _id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
bed_type: 'Real Bed',
property_type: 'house',
reviews: [58663741, 62413197, ...]
}{
{
"_id": "58663741",
"date": {
"$date": "2016-01-03T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "51483096",
"reviewer_name": "Cátia",
"comments": "..."
},
{
"_id": "62413197",
"date": {
"$date": "2016-02-14T05:00:00.000Z"
},
"listing_id": "10006546",
"reviewer_id": "40031996",
"reviewer_name": "Théo",
"comments": "..."
}
{...},
{...},
...
}La scelta del metodo più idoneo dipende molto dal numero di documenti e dal tipo di query da eseguire. In alcuni casi può essere sufficiente annidare tutti i documenti all’interno di un array in particolar modo se effettuiamo principalmente operazioni di lettura e se un’applicazione necessita di tutti i campi presenti in quel documento. Ma se le dimensioni dei documenti primari crescono notevolmente o per evitare eccessive ridondanze può essere utile valutare gli altri approcci presentati.
Relazioni molti a molti
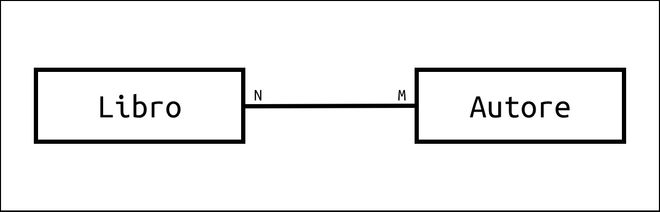
La relazione molti-a-molti si ha quando più documenti primari possono essere associati a molti altri documenti secondari e viceversa.
Consideriamo la relazione fra dei libri e gli autori. Un libro può essere scritto da più autori, ma nello stesso tempo un autore può scrivere vari libri nel corso della sua carriera.
Nei database tradizionali rappresentiamo questo tipo di relazioni introducendo una tabella di supporto e convertendo essenzialmente una relazione molti a molti in due relazioni uno a molti.
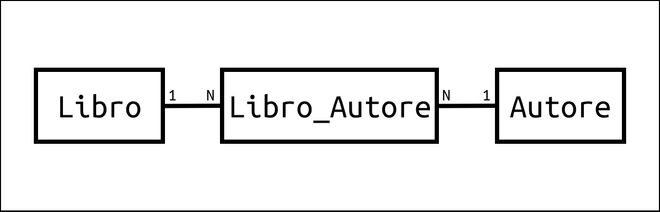
In MongoDB possiamo realizzare questo tipo di relazioni con gli strumenti che abbiamo già incontrato nei due casi precedenti.
- documenti annidati
- array di riferimenti a documenti esterni
A seconda del tipo di query, sia in uno che nell’altro caso, possiamo incorporare i documenti o gli identificativi in entrambi i lati della relazione o in un lato solo che è quello su cui effettuiamo le interrogazioni.
Supponiamo per esempio di avere due collezioni ‘books’ e ‘authors’. Nel caso volessimo creare una relazione attraverso dei documenti annidati, potremmo aggiungere un campo ‘authors’ di tipo array in ogni documento della collezione ‘books’ e un campo ‘books’ sempre di tipo array nei documenti della collezione ‘authors’. Nella collezione ‘books’ ogni elemento dell’array dovrebbe essere un documento relativo agli autori del libro. Al contrario nella collezione ‘authors’ avremmo un array ‘books’ relativo ai libri scritti da un autore.
Se le query effettuate si rivolgessero principalmente alla collezione ‘books’, potremmo limitarci ad includere dei documenti annidati solo nel campo ‘authors’ dei documenti della collezione ‘books’.
Nel caso molti-a-molti, i documenti annidati possono però generare dati duplicati e occupazione eccessiva dello spazio di archiviazione.
Per questo motivo potremmo limitarci ad includere in una o entrambi le collezioni solo dei riferimenti ai documenti della collezione esterna.
Ritornando all’esempio delle collezioni ‘books’ e ‘authors’, potremmo avere un campo di tipo array ‘authors’ nella collezione ‘books’ che conterrebbe solo gli identificativi relativi agli autori di un libro. Allo stesso modo potremmo aggiungere un campo ‘books’ alla collezione ‘authors’ con i riferimenti ai documenti relativi ai libri scritti da ciascun autore. Anche in questo caso, a seconda del tipo di query può essere sufficiente avere un campo array di riferimenti solo nei documenti della collezione ‘books’ o solo in quelli della collezione ‘authors’.
Inoltre nel caso in cui usassimo solo degli identificativi relativi ai documenti di un’altra collezione e volessimo ottenere le informazioni complete, dovremmo usare un operatore come $lookup o effettuare due query separate.
Altri Pattern per strutturare i documenti
Per concludere questa lezione illustriamo brevemente tre diversi pattern che possono risultare utili nella definizione della struttura dei documenti per limitare la loro dimensione o per velocizzare le operazioni di lettura.
Extended Reference pattern
L’Extended Reference pattern è utile in quei casi in cui esiste una relazione fra due documenti che però appartengono a collezioni diverse. Se non vogliamo annidare una copia di un documento nell’altro perché magari contiene troppi campi che non sono tutti necessari per il tipo di query effettuate e non intendiamo usare dei riferimenti perché non vogliamo unire dei documenti appartenenti a collezioni diverse, abbiamo una terza opzione che ha lo scopo di velocizzare le operazioni di lettura includendo in un documento una copia dei campi dell’altro documento.
Infatti, se per il tipo di query che eseguiamo su un documento primario sono necessari solo alcuni campi di quello secondario, possiamo introdurre un nuovo campo nel primo documento che contiene solo le informazioni necessarie.
Per esempio supponiamo di avere una collezione ‘companies’ in cui sono presenti dei documenti che includono numerosi campi relativi a delle aziende.
{
"id": 1024
"name": "Lamborghini",
"founder": "Ferruccio Lamborghini",
"website": "https://www.lamborghini.com/",
"twitter_username": "...",
"facebook_username": "...",
"instagram_username": "...",
"founded_year": 1963,
"description": "",
"mission": "",
"history": "",
"cars": {},
"dealerships": {},
"logo": "",
...
}E immaginiamo di avere un’altra collezione ‘cars’ in cui troviamo dei documenti con i dati di alcune auto storiche. Se non abbiamo bisogno di tutti i dati di una casa automobilistica, ma solo del nome, dell’anno di fondazione e del fondatore, possiamo aggiungere soltanto i campi necessari alla collezione ‘cars’.
{
"model": "Miura",
"year": 1970,
"value": 1000000,
"make": {
"name": "Lamborghini",
"founded_year": 1963,
"founder": "Ferruccio Lamborghini"
}
}Così facendo riusciamo ad accedere più velocemente ai dati richiesti perché tutti i campi necessari sono in un unico documento e non dobbiamo preoccuparci di prelevarli da un altro documento di una diversa collezione. Se però le informazioni incorporate cambiassero spesso, avremmo il problema di dover aggiornare i documenti in due diverse collezioni.
Computed Pattern
Per capire come può aiutarci questo pattern, facciamo di nuovo riferimento ad una collezione in cui sono presenti i documenti relativi a diversi alloggi.
Ciascun documento contiene inoltre un campo di tipo array con dei documenti relativi alle recensioni lasciate dai clienti.
{
_id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
property_type: 'house',
reviews: [...]
}Se in un’applicazione volessimo mostrare una scheda di valutazione per ogni alloggio con la media dei voti assegnati dai singoli clienti, potremmo calcolare ogni volta il valore medio in base ai punteggi delle diverse valutazioni dei clienti. Questa operazione sarebbe dispendiosa in particolar modo per gli alloggi con numerose valutazioni. Significherebbe dover salvare i singoli voti degli utenti e ripetere ogni volta il calcolo della media dei voti.
Dal momento che siamo interessati al punteggio medio, possiamo aggiungere a ciascun documento un campo che contiene solo questi dati.
{ _id: '10006546',
name: 'Ribeira Charming Duplex',
// ...
// ...
bed_type: 'Real Bed',
property_type: 'house',
review_scores: {
review_scores_accuracy: 9,
review_scores_cleanliness: 9,
review_scores_checkin: 10,
review_scores_communication: 10,
review_scores_location: 10,
review_scores_value: 9,
review_scores_rating: 89
},
reviews: [...]
}L’aspetto negativo è che per ciascuna nuova valutazione da parte di un utente, dovremo aggiornare il punteggio medio dell’abitazione.
In compenso tutte le volte che viene visualizzata la pagina descrittiva di una certa proprietà, possiamo eseguire soltanto la lettura e prelevare direttamente la media dei voti dal documento corrispondente senza dover ripetere calcoli superflui.
Attribute Pattern
L’Attribute Pattern è particolarmente utile nei casi in cui si abbiano documenti di grandi dimensioni con campi simili che condividono caratteristiche comuni. Se volessimo eseguire query o se volessimo ordinare i risultati in base ai suddetti campi, avremmo bisogno di creare degli indici per ciascuno di essi al fine di migliorare la velocità di esecuzione delle letture o per evitare dispendiose operazioni di ordinamento in memoria.
Supponiamo allora di avere una collezione ‘products’ con dei documenti simili a quello mostrato sotto.
{
"make": "AmazingKeyboard",
"model" "k123"
"sku": "80029",
"colors": ["blue", "black", "white"],
"priceUS": 100.00,
"priceUK": 99.00,
"priceSpain": 119.00,
"priceGermany": 119.00,
"priceItaly": 149.00
}Se volessimo eseguire delle operazioni di ordinamento o ricerca in base al prezzo, dovremmo creare tanti indici quanti sono i prezzi nelle diverse nazioni.
Al contrario, usando l’Attribute Pattern, sostituiamo i diversi campi relativi ai prezzi con un unico campo di tipo array che contiene dei documenti con i dettagli dei costi in base alle diverse nazioni. Ciascun documento presenta gli stessi campi a cui assegniamo ovviamente valori diversi.
{
"make": "AmazingKeyboard",
"model" "k123"
"sku": "80029",
"colors": ["blue", "black", "white"],
"prices": [
{ "country": "United States", "amount": 100.00, "currency": "USD" },
{ "country": "United Kingdom", "amount": 99.00, "currency": "GBP" },
{ "country": "Spain", "amount": 119.00, "currency": "EUR" },
{ "country": "Germany", "amount": 119.00, "currency": "EUR" },
{ "country": "Italy", "amount": 149.00, "currency": "EUR" }
]
}Sostanzialmente per ogni campo (es. ‘priceUS’) abbiamo creato un oggetto di coppie chiavi-valore in cui però le chiavi hanno tutte lo stesso nome.
Così facendo, possiamo ridurre il numero di indici e crearne uno solo con i soli campi dei documenti dell’array.
{ "prices.country": 1, "prices.amount": 1, "prices.currency": 1 }L’Attribute Pattern permette così di ridurre il numero di campi da indicizzare e semplificare la struttura dei documenti.
In generale l’Attribute Pattern è utile per tutti i documenti che hanno una serie di campi accomunati da una certa caratteristica e che hanno valori simili tali da poter essere organizzati in array di documenti con campi aventi lo stesso nome.
Nella prossima lezione…
Nella prossima lezione vedremo come creare degli utenti per i database in MongoDB e come definire ed assegnare dei ruoli predefiniti al fine di aumentare il livello di sicurezza e limitare l’accesso ai dati presenti nelle collezioni.