Ruby è un linguaggio ad oggetti che sta ricevendo sempre più consensi per le sue caratteristiche di semplicità e immediata produttività, nonchè per la diffusione di alcuni frameworks, Ruby on Rails su tutti, che ne sfruttano le potenzialità.
Ruby è nato nel 1993 in Giappone dalla mente di un programmatore nipponico, Yukihiro Matsumoto soprannominato "Matz", che ne ha realizzato l’interprete in C e lo ha rilasciato sotto una licenza molto simile a quella Open Source. Inizialmente Ruby non riscosse un grande successo, Matsumoto infatti non era un programmatore professionista e il suo lavoro faticava a trovare riscontri positivi; le caratteristiche intrinseche al linguaggio finirono però per essere molto apprezzate e presto Ruby divenne uno strumento importante anche per i tecnici di aziende ed enti di fama mondiale come la Motorola e la NASA.
Ruby è stato concepito con tre obbiettivi principali:
- mettere a disposizione degli sviluppatori un linguaggio semplice che permettesse di riscoprire la gioa di programmare;
- sfruttare la programmazione a oggetti in modo da ridurre al minimo la lunghezza del codice da digitare;
- creare un linguaggio che permettesse di essere velocemente produttivi; Ruby può essere infatti imparato come primo linguaggio grazie all’estrema faciltà nel passaggio dalla teoria alla pratica.
A differenza di altri linguaggi, Ruby mette a disposizione un interprete nativo per piattaforme Windows, in questo modo non ci si dovrà preoccupare di possibili differenze nelle prestazioni tra sistemi operativi.
Concettualmente Ruby non è un linguaggio rivoluzionario, presenta infatti caratteristiche comuni ad altre realtà affermate come Smalltalk (da cui pare Matsumoto abbia preso ispirazione), Perl (con cui ha molti aspetti in comune) e Python.
Si tratta di un linguaggio interpretato cioè scritto in puro testo e tradotto ad ogni esecuzione da un programma chiamato interprete; inoltre è orientato agli oggetti (OOP), architettura che presuppone che ogni entità utilizzata sia un oggetto dotato di proprietà metodi. Ruby è un linguaggio multipiattaforma e potrà essere utilizzato senza particolari problemi in Linux, in Windows e su Mac OS così come in altri sistemi operativi meno conosciuti.
Principali caratteristiche di Ruby
Ruby non è un linguaggio rivoluzionario, ma è dotato si alcune caratteristiche che possono risultare molto interessanti per il suo utilizzo in sede di programmazione:
- è un linguaggio orientato agli oggetti, per cui si basa su un’architettura in cui ogni entità utilizzata è un oggetto dotato di proprietà e metodi;
- è molto semplice da imparare e da utilizzare, il suo creatore lo ha concepito come uno strumento che restituisse agli sviluppatori la gioia di programmare;
- può essere imparato come primo linguaggio, per utilizzare Ruby non saranno necessarie precedenti esperienze nel campo della programmazione, inoltre, permette di essere operativi in pochissimo tempo.
Installazione in ambienti Windows e Linux
Come anticipato Ruby è un linguaggio estremamente semplice e questo discorso è valido anche per le operazioni relative alla sua installazione e configuarazione.
Per quanto riguarda gli ambienti Windows, chi ha voglia di imparare questo linguaggio ha la possibilità di dotarsi di un ambiente di lavoro completo grazie al One-Click Ruby Installer for Windows distribuito gratuitamente nell’apposita sezione download di Rubyforge.
Nel momento in cui scriviamo, l’ultima versione stabile è la numero 1.8.6-26 è sarà questa che utilizzaremo per i nostri esempi.
Una volta scaricato l’eseguibile (poco più di 23 Mb), basterà un click per avviare la procedura guidata d’installazione. La prima richiesta che ci verrà fatta dal calssico Wizard sarà quella di accettare la licenza di utilizzo, basterà clickare su "I Agree" per andare avanti.
Ora l’installer ci chiederà quali componenti desideriamo installare insieme a Ruby (l’unico obbligatorio); le altre voci sono
- SciTE (SCIntilla based Text Editor), un editor testuale che supporta la colorazione del codice
- RubyGems, un gestore di pacchetti per Ruby che mette a disposizione uno standard per distribuire i programmi e le librerie scritti in questo linguaggio
- Tastiera europea con supporto per il keybord mapping
Lasciamo pure selezionate le prime 3 voci e andiamo avanti; indichiamo la cartella che ospiterà i file post-installazione e scegliamo se far partire Ruby in Start Up passando poi alla vera e propria procedura di installazione. L’ultima fase non è molto lunga ma verranno estratti un bel pò di packages, alla fine la cartella dovrebbe contenere circa 90 Mb di file. Ora Ruby è pronto per essere utilizzato.
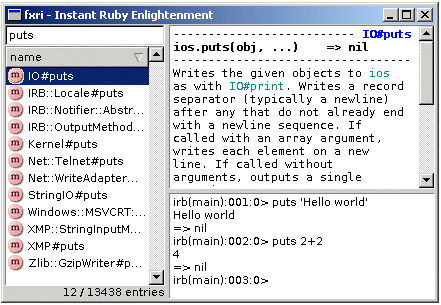
Dal menu start potrete far partire la console di Ruby (Frixi) e cominciare a programmare:
In Linux il discorso è altrettanto semplice; se volete installare Ruby nel Pinguino avrete due possibilità: utilizzare il sistema di gestione delle installazioni RPM oppure compilare i sorgenti.
Nel primo caso potrete scaricare l’apposito ".rpm" da questo repository (la versione cambia a seconda della vostra distro) e procedere all’installazione con un semplice comando che si occuperà di tutto:
rpm -Uhv ruby-*.rpmNel caso dei sorgenti invece ci sarà da affrontare qualche passaggio in più:
cd /usr/src
wget http://mirror.rubyforums.com/ruby/ruby-*.tar.gz
tar xfz ruby-latest.tar.gz
cd ruby-1.8.*
./configure --prefix=/usr
make
make installSe tutto è andato per il meglio, digitando:
ruby -vverrà visualizzata la versione di Ruby presente nel sistema
La seconda procedura è comunque consigliata solo per i più esperti.
Come Ruby vede le stringhe
Nell’immagine riportata nel capitolo precedente è stata mostrata una schermata della shell di Fxri; questo programma è estremamente semplice da utilizzare: sulla sinistra è possibile richiamare comandi e costrutti con un pratico motore di ricerca (oltre 13 mila voci); sulla destra in alto avremo una descrizione della voce che abbiamo cercato; sulla destra in basso abbiamo invece la vera e propria Shell in cui digitare le istruzioni in Ruby.
Ora portiamo il puntatore del mouse sulla Shell e digitiamo la semplice istruzione:
puts 'Hello, world!'Con un semplice invio avremo in output la stringa:
Hello, world!"Smontiamo" il nostro primo scriptino in Ruby:
- puts è un’istruzione per la stampa di un argomento passato come parametro (come echo e print in PHP)
- gli apici (‘…’), detti anche quotes, come nella sistassi tipica di altri linguaggi (ad esempio Perl) delimitano un determinato parametro per indicare che esso è una stringa
- Al termine dell’istruzione non vi è un delimitatore di chiusura; non abbiamo per esempio il ";" che chiude un’istruzione in altri linguaggi. Si tratta di una delle tante semplificazioni che Ruby mette a disposizione dello sviluppatore
Ruby, come PHP, accetta sia gli apici singoli (‘…’) che quelli doppi ("…"). Queste due tipologie di definizione delle stringhe non sono totalmente intercambiabili perchè generano comportamenti diversi a seconda dei casi.
Una stringa contenuta tra doppi apici consente di utilizzare i caratteri di escape preceduti da un backslash ("") e l’interpretazione di espressioni in cui è presente il costrutto #{} per l’interpolazione che vedremo a breve. Una stringa tra apici singoli non genera interpretazioni quindi la stringa verrà stampata esattamente nella forma in cui viene passata all’esecutore.
"puts" non è l’unica istruzione per la stampa di Ruby; analogamente, ma con alcune caratteristiche distintive, possono essere utilizzati anche p e print.
"print" viene considerato un "puts di basso livello" (senza accezioni qualitative); "p" permette il dump delle variabili e il loro quoting.
All’interno di un listato in Ruby è possibile inserire dei commenti, cioè "annotazioni" dello sviluppatore che non sono destinate a partecipare all’esecuzione del programma nè ad essere stampate. Per introdurre dei commenti nel codice è possibile utilizzare due metodi: porre il simbolo dell’asterisco all’inizio di un commento (per i commenti su riga singola) o scrivere più righe di commento all’interno dei deilimitatori =begin e =end:
# puts aggiunge n se necessario:
puts 'Hello World!'
puts 'Come va?'
=begin
print non inserisce newline nelle stringhe di output
questo deve essere indicato dallo sviluppatore
ad esempio:
=end
print "Hello Worldn"
print "Ciao"Utilizzando Fxri per stampare la vostra prima stringa avrete sicuramente notato nella Shell la presenza di due voci: irb(main) e nil.
IRB (Interactive Ruby) è un REPL (Read-Eval-Print Loop), cioè un interprete che lavora in modalità interattiva consentendo di tenere traccia dei risultati delle proprie istruzioni; un REPL prevede 4 fasi:
- read (lettura di un’istruzione)
- eval (esecuzione)
- print (stampa del risultato)
- loop (iterazione)
Per velocizzare le fasi di sviluppo l’interprete si occupa di definire una classe automaticamente, main, che sarà anche il nome del modulo corrente; nil è invece un valore speciale (come null in Java) dato dal fatto che "puts" non necessita di restituire un valore utile e di conseguenza restituisce "nil".
Come Ruby vede i numeri: sintassi e operatori
Per eseguire istruzioni scritte in Rubyè possibile utilizzare due metodi: quello già visto in precedenza dove vengono passate le istruzioni alla Shell o, in alternativa, la creazione di file di testo contenenti le istruzioni da eseguire; se si utilizza il secondo metodo i file potranno essere salvati tramite un’estensione dedicata chiamata ".rb".
Prendiamo una semplice istruzione matematica come la seguente:
puts 2+2Questa potrà essere passata direttamente in Shell ed eseguita con un [Invio] oppure salvata in un file chiamato ad esempio "addizione.rb"; se si è scelta la strada del salvataggio in un file, l’istruzione contenuta al suo interno potrà essere eseguita tramite una semplice operazione di richiamo:
ruby addizione.rbQualunque sia la modalità scelta, il risultato restituito dall’interprete sarà naturalmente "4"; la nostra istruzione è infatti perfettamente analoga alla seguente:
puts 4Questo discorso ci permette di osservare in quale modo Ruby gestisce i numeri; se si conoscono altri linguaggi di programmazione o di scripting come Perl e PHP sarà possibile notare come il comportamento di Ruby con le cifre sia praticamente identico.
Infatti, a differenza di quanto succede per le stringhe, per introdurre un numero in un’istruzione questo non deve essere delimitato da apici; facciamo un esempio:
# questo è un numero
puts 10
# questa è una stringa
puts '10'Perchè la differenza sia ancora più chiara, proviamo ad eseguire queste due istruzioni:
# operazione matematica
puts 10 - 4
# stampa di una stringa
puts '10 - 4'L’output della prima istruzione sarà "6", mentre quello della seconda sarà "10-4"; infatti nel primo caso "10" e "4" sono visti come due operandi e "-" come l’operatore che dovrà determinare la differenza tra i due numeri; nel secondo caso invece "10 – 4" non è altro che una sequenza di caratteri (cioè una stringa) e come tale viene trattata.
L’utilizzo degli spazi all’interno di un’espressione matematica non è rilevante ai fini del funzionamento dello script, se ne consiglia comunque l’impiego per rendere il codice più leggibile.
Come per altri linguaggi, Ruby considera l’esistenza di due tipologie di numeri: gli interi (integer) e i decimali (floating point o semplicemente float). I primi non hanno regole particolari, i secondi devono essere indicati separando i numeri a sinistra e a destra della virgola con un punto, ad esempio:
puts 5.30 - 8.30L’operazione che avrà come risultato un numero negativo pari a "-3.0".
Per quanto riguarda gli operatori utilizzabili nelle operazioni aritmetiche di Ruby, questi sono quelli classici:
# addizione
puts 5 + 4
# sottrazione
puts 5 - 4
# moltiplicazione
puts 5 * 4
# divisione
puts 5/4Un discorso particolare è quello relativo agli arrotondamenti; se eseguissimo con una clacolatrice l’ultima operazione presente nell’esempio appena proposto il risultato della divisione sarebbe "1,25", Ruby invece restituirà semplicemente "1". L’interprete è cioè predisposto per l’arrotondamento dei decimali nelle operazioni di divisione.
Variabili e conversioni in Ruby
Un concetto molto importante in programmazione, non soltanto per Ruby, è quello relativo alle variabili. Queste sono dei veri e propri contenitori di informazioni che permettono di conservare nella memoria di un terminale un determinato valore attraverso una semplice operazione di associazione.
Una variabile è quindi un sequenza di caratteri (lettere e numeri) che punta ad un determinato valore; richiamando una variabile sarà possbile quindi richiamare anche il valore che essa contiene.
Un caso importante è quello relativo alle variabili locali, esse non sono altro che delle semplici parole che devono avere il carattere iniziale minuscolo o un underscore ("_") e possono contenere anche delle cifre. Se l’interprete del linguaggio vede una parola chiave impostata come una variabile locale la può interpretare come una keyword, come una chiamata ad un metodo o appunto come una variabile locale.
Le keywords in Ruby sono delle vere e proprie parole riservate che non possono essere utilizzate come nomi per le variabili in quanto sono destinate a definire un metodo o un altro costrutto. "for" e "while" richiamano dei cicli, "if" ed "else" delle condizioni, dato che questi costrutti sono molto utilizzati in Ruby si è preferito riservarli in modo che non potessero essere confusi con i nomi delle variabili. Ruby presenta 38 reserved words la cui lista potrà essere consultata all’inizio di questa pagina.
Semplici istruzioni come "puts" o "print", viste in precedenza, sono delle chiamate per i metodi, ma possono essere anche parte di una variabile locale; in questo caso dovrà essere l’interprete di Ruby a identificarle nel modo corretto:
- nel caso in cui alla destra del termine sia presente un segno uguale ("=") avremo una variabile locale e verrà effettuata l’assegnazione di un valore
- se invece il termine è elencato tra le keywords di Ruby, questo non potrà essere considerato come una chiamata ad un metodo
Ora passiamo ad un altro argomento importante, l’assegnazione di valori alle variabili; questo avviene tramite l’utilizzo dell’operatore di assegnazione "=", vediamo un esempio
# assegnazione di un valore numerico
var1 = 5
# assegnazione di un valore stringa
var2 = '5'La variabile "var1" contiene un valore numerico, la variabile "var2" contiene invece un valore stringa; i due valori non possono quindi essere sommati perche rapprentano due tipologie di dato differenti. Vediamo ora un secondo esempio:
# assegnazione di valori a due variabili
var1 = 5
var2 = 5
puts var1 + var2In questo caso l’operazione svolta è invece possibile in quanto le due variabili sono compatibili per tipo di dato che rappresentano; l’operazione di addizione viene svolta utilizzando le variabili e non direttamente i valori che essere rappresentano, con indubbi vataggi nella manipolazione di valori complessi (ad una varibile potrebbe per esempio corrispondere un valore composto da molte cifre o da molti caratteri alfanumerici).
I tipi di dato non sono però degli ostacoli invalicabili, è possibile infatti operare delle conversioni tra i dati grazie a dei semplici operatori di conversione; facciamo un esempio:
# conversione di variabili
var1 = 5
var2 = '5'
puts var1.to_s + var2"var1.to_s" permette di convertire il valore di "var1" (che è un numerico intero) in una stringa; il risultato dell’operazione sarà quindi la stringa "25"; se to_s consente la conversione di interi in stringhe, per effettuare l’operazione contraria abbiamo a disposizione l’operatore to_i così come abbiamo to_f per la conversione di interi in float. Da notare che la conversione del valore non determina una riassegnazione, la variabile conserverà quindi il tipo di dato assegnato tramite l’operatore "=".
Utilizzo dei metodi gets e chomp e distinzioni tra variabili
In questa lezione della nostra guida Ruby analizzeremo il funzionamento dei metodi gets e chomp. Per entrare nel merito della questione si osservi questo semplice listato:
# utilizzo del metodo gets
nome = gets
Carla
puts = 'Ciao ' + nome + ' come stai?'l’output prodotto dalla sua esecuzione sarà il seguente:
Ciao Carla come stai?
gets è un metodo a cui può essere associato un qualsiasi valore digitato dopo la pressione del tasto [Invio]; nel nostro esempio abbiamo associato alla variabile "nome" il parametro "Carla" passato a "gets", nell’istruzione di stampa quindi ciò che otteniamo è una stringa in cui la variabile viene interpretata restituendo il valore associato al metodo.
Da notare come in questo caso il segno "+" non svolga naturalmente il ruolo di operatore di addizione ma quello di concatenazione tra variabili e stringhe; il fatto che la seconda stringa, cioè "come stai" venga scritta a capo non è casuale, "gets" aggiunge infatti una newline ("n") al valore della variabile che memorizza, conseguentemente quello che dovrà essere stampato dopo sarà compreso in una seconda riga.
Questa particolarità pone alcuni problemi di formattazione, del resto perchè dividere l’output in più righe se l’utente non lo desidera? Ruby per questo motivo mette a disposizione l’apposito metodo chomp che impedisce la creazione di una seconda riga dopo la stampa della variabile.
Facciamo un esempio:
# utilizzo di gets e chomp
nome = gets.chomp
Carolina
puts = 'Buonasera, ' + nome + ' è occupata?'Dall’esecuzione del nostro secondo esempio otterremo l’output:
Buonasera, Carolina è occupata?
sicuramente più gradevole del primo a livello di formattazione.
Nel corso di questa trattazione abbiamo utilizzato più volte il termine variabili e ne abbiamo analizzato l’utilizzo; a questo punto è bene introdurre alcune distinzioni tra tipologie di variabili per non ingenerare confusioni nei prossimi esempi. In linea generale possiamo dire che le variabili si distinguono sulla base del loro nome:
- il nome di una variabile locale è formato da un carattere minuscolo seguito dagli altri caratteri, come ad esempio "_abc", "leggi_il_file" etc.
- per una variabile di istanza di un’oggetto avremo invece la "@" come carattere iniziale, questa sarà seguita da un altro carattere che potrà essere maiuscolo o minuscolo, come per esempio "@var", "@_" e "@Var";
- nel caso delle variabili di classe, cioè dichiarate nel contesto di una classe, il loro nome inizierà con due "@@", seguite da un carattere maiuscolo o minuscolo opzionalmente seguito altri caratteri, come per esempio "@@var", "@@_" oppure "@@var"
- le variabili globali, quelle valide per tutta l’applicazione, hanno un nome che inizia con il segno di dollaro ("$") seguito da caratteri diversi come per esempio: "$var", "$VAR" e "$-var"
Un caso particolare è quello relativo alle costanti, a differenza delle variabili esse non dovrebbero modificare il valore a loro assegnato, un tentativo di riassegnazione porterà si all’attribuzione di un nuovo valore, ma anche alla notifica di un errore.
In Ruby una costante si riferisce ad un oggetto e viene creata con un’operazione di assegnazione di valore, il nome di una costante inizia con una lettera maiuscola seguita da altri caratteri, ad esempio:
#assegnazione di un valore ad una costante:
A_CONST = 100Istruzioni condizionali in Ruby
Le istruzioni condizionali sono presenti praticamente in ogni linguaggio di programmazione e di scripting. Esse ci consentono di controllare il flusso dei dati ponendo condizioni ed alternative a cui corrispondono differenti comportamenti da parte del codice digitato e della sua interpretazione.
Affrontiamo subito l’argomento con un semplice esempio basato sul costrutto if – else – end:
# uso del costrutto if - else
# definiamo una variabile
num = 10
# stabiliamo una condizione
if num > 9
# se la condizione è soddisfatta allora stampa..
puts 'Valore superiore a 9.'
# poniamo un'alternativa alla condizione
else
# se la condizione non è soddisfatta allora stampa..
puts 'Valore non superiore a 9.'
# chiudiamo il blocco if - else
endCopiate e incollate lo scriptino ed eseguitelo dopo avergli dato un nome (ad esempio "condizioni.rb"). L’output restituito dall’interprete di Ruby sarà:
Valore superiore a 9.Per chiarire quanto mostrato smonteremo ogni riga di codice del nostro scriptino:
- innanzitutto abbiamo definito una semplice variabile a cui abbiamo associato un valore numerico intero pari a "10"
- in secondo luogo abbiamo introdotto una condizione: se ("if") il valore della variabile dovesse essere superiore a "9" allora dovrà essere stampata la stringa "Valore superiore a 9."
- dato che il valore della variabile è effettivamente superiore a 9 verrà stampata la stringa stabilita in condizione
- ma se invece ("else") il valore della variabile dovesse essere inferiore o uguale a "9" cosa succederebbe? Verrebbe stamapata una semplice stringa alternativa: "Valore non superiore a 9"
- stabilite condizioni e le alternative non ci rimane altro che chiudere l’applicazione ("end")
L’esempio utilizzato ci permette anche di introdurre un semplice ma fondamentale argomento riguardante gli operatori di confronto, alcuni di essi sono stati già utilizzati nello script:
- "==": operatore di identità, significa "è identico a.."
- "!": operatore di diversita, significa "non è uguale a.."
- ">": operatore di maggioranza, significa "è superiore a .."
- "<": operatore di minoranza, significa "è inferiore a.. "
Gli operatori di confronto possono essere utilizzati anche in combinazione con quello di assegnazione ("="); in questo modo l’utilizzo associato di ">=" significa "maggiore o uguale a.. " e quello di "<=" significa "minore o uguale a…"
Le condizioni proposte da un blocco di codice possono essere anche più di una;è per esempio possibile introdurre l’istruzione elsif (attenzione! non "elseif") che pone una condizione alternativa a quella introdotta da "if"; mentre l’alternativa posta da "else" si verifica in tutti i casi in cui la condizione di "if" non è vera , quella di "elsif" si verifica solo quando è vera una precisa condizione diversa da quella di "if". Vediamo un semplice esempio:
# uso del costrutto if - elsif - else
# definiamo una variabile
nome = 'Chiara'
# stabiliamo una condizione
if nome == 'Carla'
# se la condizione è soddisfatta allora stampa..
puts 'Ciao Carla, come stai?'
#stabiliamo una condizione alternativa
elsif nome == 'Monica'
# se la seconda condizione è soddisfatta allora stampa..
puts 'Ciao Monica, come stai?'
# poniamo un'alternativa alla condizione
else
# se nessuna condizione è soddisfatta allora stampa..
puts 'Ciao Chiara, come stai?'
# chiudiamo il blocco if - elsif - else
endL’esecuzione del nostro secondo esempio porterà alla stampa della stringa: "Ciao Chiara, come stai?". Perchè?
Semplicemente perchè nessuna della due condizioni introdotte da "if" e "elsif" è vera (la variabile non è identica nè a "Carla" nè a "Monica"), quindi l’unico esito possibile sarà quello proposto come alternativa da "else".
Chi conosce altri linguaggi di programmazione e scipting avrà notato similitudini e differenze nella sintassi utilizzata:
- in Ruby le condizioni e le alternative non vanno scritte all’interno delle parentesi
- le condizioni alternative non si introducono con "else if" o "elseif" come per esempio in PHP ma con "elsif" come in Perl
- l’operatore di assegnazione ("=") e di identità ("==") sono differenti, se utilizzassimo il primo in luogo del secondo modificheremmo il valore della relativa variabile sconvolgendo l’esito della nostra applicazione
- in alcuni linguaggi come PHP, utilizzare l’operatore di assegnazione in una condizione significa semplicemente riassegnare il valore ad una variabile; anche in Ruby avviene questo, ma non prima di aver ricevuto una notifica di errore
Strutture di controllo unless e case
unless è un’istruzione condizionale di Ruby opposta a "if"; si tratta infatti di un’istruzione che permette di dar vita ad un determinato comportamento sulla base di una condizione non soddisfatta ("falsa").
Per spiegare meglio il funzionamento di "unless" proponiamo un semplice esempio:
# costrutto unless
# definiamo una variabile
i = 3
# stabiliamo una condizione
unless i >= 10
puts "Prima condizione"
# introduciamo un'alternativa
else
puts "Seconda condizione"
# chiudiamo il blocco unless - else
endL’output del nostro script sarà "Prima condizione", infatti "unless" consente di verificare che una condizione non sia soddisfatta; nel nostro caso infatti la variabile "i" non è nè maggiore nè uguale a "10".
"unless" permette anche di essere utilizzata con una sintassi alternativa:
# condizione unless
# sintassi semplificata
i = 3
puts 'i è maggiore di 5' unless i >= 5La stessa tipologia di sintassi potrà essere utilizzata anche per l’istruzione "if":
# costrutto if
# sintassi semplificata
i = 5
puts 'i è maggiore di 3' if i >= 3Sempre riferendoci all’struzione if è possibile attuare un’ulteriore semplificazione a livello sintattico con un piccolo sacrificio a carico della leggibilità del codice:
# costrutto if
# sintassi semplificata
i = 5
puts val = i == 5 ? 'uguale' : 'diverso'L’operatore "?" ci permette infatti di effettuare un controllo tra valori; nel nostro esempio abbiamo stabilito che la variabile "i" è associata al valore "5", lo scriptino stabilisce che se ("?") "i" è identica a "5" dovrà essere stampata la stringa "uguale", diversamente (":"), dovrà essere stampata la stringa "diverso". L’output sarà naturalmente "uguale".
case è un costrutto che può essere utilizzato spesso come alternativa ad "if" ed "unless", utilizza infatti una struttura in grado di poter gestire più eventi definiti dall’utente; vediamo un semplice esempio:
# costrutto case - when
# definizione della variabile
nome = 'Carla'
# introduzione dei possibili casi
case nome
when 'Carla'
puts 'Ciao Carla'
when 'Monica'
puts 'Ciao Monica'
# alternativa
else
puts 'Ciao!'
# chiusura del blocco case - when
endIn pratica una volta stabilito il valore di una variabile è possibile introdurre diversi eventi che si verificheranno quando (when) una determinata condizione verrà soddisfatta. Anche "case" consente l’introduzione di un’alternativa con "else", si tratta infatti di un costrutto condizionale esattamente come "if" o "unless".
Nello stesso modo, anche per "case" è naturalmente possibile utilizzare una sintassi semplificata:
# costrutto case - when
# sintassi semplificata
# definizione della variabile
i = 5
# introduzione dei possibili casi
case i
when i > 6: puts 'Maggiore di 6'
when i == 6: puts 'Minore di 6'
# alternativa
else puts 'Uguale a 5'
# chiusura del blocco case - when
endI cicli in Ruby
I cicli sono dei costrutti comuni a tutti i linguaggi di programmazione e di scripting; essi non sono altro che delle iterazioni che si verificano fino a quando non viene soddisfatta una determinata condizione.
Uno dei cicli più utilizzati in Ruby (e non solo) è while, grazie ad esso è possibile produrre più output sulla base di una condizione iniziale, vediamone un semplice esempio:
# ciclo while
# definizione della variabile
i = 0
# condizione
while i < 5 do
print i , ' '
i+= 1
# chiusura del ciclo while
endIl codice proposto è abbastanza semplice: una volta stabilito il valore da associare ad una variabile ("i=0"), abbiamo richiesto allo script di stampare tutti i valori d’incremento unitario fino ad una cifra inferiore a "5". L’output sarà quindi:
0 1 2 3 4Da notare come:
- abbiamo utilizzato "print" al posto di "puts" per evitare che nell’output fossero inserite newline che mandassero a capo i numeri
- abbiamo richiesto con una stessa istruzione la stampa di un intero e di una stringa (nel nostrio caso vuota) separandole con una virgola ("print i , ‘ ‘")
- l’utilizzo del segno "+" associato ad una variabile definita e ad un valore ("i+= 1") ha permesso di stabilire un incremento
- attenzione! L’incremento necessita il costrutto "n+= val" , separare "+" da "=" determina la notifica di un errore
Un ciclo può naturalmente essere interrotto sulla base di un’ulteriore condizione; per fa questo abbiamo a disposizione il costrutto break:
# ciclo while con interruzione
# definizione della variabile
i = 0
# condizione
while i < 5 do
print i , ' '
i+= 1
# interruzione del ciclo
break if i == 3
# chiusura del ciclo while
endNell’esempio appena proposto abbiamo stabilito grazie a "break" che una volta raggiunto un valore pari a "3" il ciclo deve esse interrotto, non ci sarà quindi una nuova iterazione che porterà alla stampa dei valori "3" e "4".
Ma se volessimo semplicemente "saltare" un passaggio del ciclo potremmo farlo? Certamente, grazie all’istruzione next:
# uso dell'istruzione next nei cicli
# definizione di una variabile
val = 0
# condizione
while val < 3
val += 1
# valore da saltare per il ciclo
next if val == 2
print val, ' ' # stampa "1 3"
# chiusura del ciclo while
endDi natura opposta a "while" è invece until, esso infatti si occupa di eseguire delle iterazioni fino a quando una condizione non risulta falsa; vediamone un esempio:
# ciclo until
i = 0
# condizione
until i == 4
print i , ' '
i += 1
# chiusura del ciclo until
endL’output prodotto dal nostro scriptino sarà:
0 1 2 3Infatti nel momento in cui la variabile assumerà un valore pari a "4" la condizione risulterà vera e il ciclo si interromperà restituendo solo i risultati per cui essa non risulta valida.
Passiamo ora all’analisi di un ultima tipologia di ciclo, for; il suo utilizzo è talmente semplice che mostreremo subito un esempio.
# ciclo for
for i in (1..5)
print i, ' '
# chiusura del ciclo for
endIn pratica abbiamo stabilito di incrementare il valore di "i" partendo da "1" (inizializzazione del ciclo) fino a "5" (condizione di terminazione); le iterazioni si fermeranno una volta raggiunto il massimo incremento consentito:
0 1 2 3 4 5Da notare come i valori di input siano stabiliti all’interno dei parametri per il ciclo, non è quindi necessario definire preventivamente la variabile da incrementare.
Gli array in Ruby
Gli array, detti anche vettori, sono delle variabili che contengono più valori; ad ogni valore incluso all’interno di un array corrisponde un determinato indice che ha la funzione di ordinare le informazioni conservate nel vettore.
In questo modo ogni valore interno ad un array si comporta come se fosse assegnato ad una comune variabile e come tale potrà essere manipolato; in base al tipo di variabili contenute è possibile operare una distinzione tra le variabili sulla base del tipo di dato, avremo quindi array di interi e array di stringhe.
Sintatticamente un array è rappresentato dal suo nome seguito da parentesi quadre che delimitano l’indice relativo al valore che desideriamo utilizzare. Quindi potremmo avere anche un array vuoto, privo di valori, e rappresentarlo in questo modo:
# un array vuoto
vettore = []Di default gli elementi interni ad un array vengono ordinati con indici numerici sequenziali che vanno da "0" ad "n"; quindi il primo valore contenuto in un array potrà essere richiamato ponendo l’indice "0" tra le parentesi quadre:
# primo valore di un array
puts vettore[0]Nel caso in cui un array contenga un solo valore potremmo stampare quest’ultimo utilizzando una sintassi come la seguente:
# array con singolo valore
vettore = [9]
puts vettore[0] # stampa "9"Se i valori contenuti nell’array sono più di uno, allora il valore desiderato potrà essere stampato semplicemente richiamandone l’indice:
# array stringa con due valori
vettore = ['Carla', 'Monica']
puts vettore[0] # stampa "Carla"
puts vettore[1] # stampa "Monica"Se si vogliono inserire più valori all’interno di un array questi devono essere separati da una virgola, nel momento in cui l’inteprete riceverà un comando per la manipolazione dei valori, ad esempio un’istruzione di stampa, la virgola non verrà presa in considerazione:
animali = ['cani', 'gatti', 'canarini', 'conigli',]
puts animali[0] # stampa "cani"
puts animali[1] # stampa "gatti"
puts animali[2] # stampa "canarini"
puts animali[3] # stampa "conigli"In ogni caso è possibile aggiungere un nuovo valore ad un array, sia esso un intero, una stringa o un ulteriore array:
# aggiungere valori ad un array
puts animali[4]
# aggiungere un valore stringa
animali[4] = 'balena'
puts animali[4] #stampa "balena"
# aggiungere un valore numerico
animali[5] = 1000
puts animali[5] #stampa "1000"
# aggiungere un array ad un array
animali[6] = ['a', 'b', 'c']
puts animali [6] #stampa "a b c"Per gli array esiste un ciclo appositamente dedicato chiamato each – do (un po’ come dire: "per ciascuno ("each") dei valori presenti nell’array fai ("do") questo.."); la sua sintassi potrà essere osservata nell’esempio seguente:
# ciclo each - do per gli array
# definiamo l'array
pianeti = ['Terra', 'Marte', 'Giove']
# stampiamo tutto il contenuto dell'array
pianeti.each do |val|
puts val + ' è un pianeta.'
# chiudiamo il blocco each - do
end"each – do" permette quindi di associare ogni valore ad un parametro che si occuperà di renderlo utilizzabile, come per esempio in un’istruzione per la stampa degli output come quella dello script appena esposto il cui risultato sarà:
Terra è un pianeta.
Marte è un pianeta.
Giove è un pianeta.Nel caso in cui si voglia invece rimuovere un valore da un array basterà utilizzare il metodo delete:
pianeti.delete('Terra')Gli hash in Ruby
Gli hash (detti anche array associativi) sono dei costrutti sostanzialmente simili agli array ma a differenza di questi utilizzano un’indicizzazione differente, non basata soltanto sui numeri interi.
Se i valori all’interno dei comuni vettori sono associati a degli indici che vanno da o a n, negli hash un indice può essere invece di qualsiasi tipo come per esempio una stringa o un’espressione regolare.
Nel momento in cui si vuole salvare un valore all’interno di un hash, è quindi necessario indicare sia l’indice che il valore ad esso associato; ne consegue che sarà possibile richiamare lo stesso valore facendo riferimento al suo indice. Facciamo un piccolo esempio:
# gli hash in Ruby
# definiamo l'hash
h = {'fiore' => 'flora', 'animale' => 'fauna'}
puts h['animale'] # stampa "fauna"
puts h['fiore'] #stampa "flora"L’hash che abbiamo definito nell’esempio è molto semplice, presenta soltanto due valori a cui sono associati due indici stringa che è possibile richiamare per ottenere le relative ad essi voci associate.
Da un hash si possono ricavare numerose informazioni interessanti, ad esempio quella riferita al numero dei valori presenti e alle diverse associazioni tra chiavi e valori; prendiamo come esempio questo semplice hash:
# recuperare informazioni da un hash
# definiamo l'hash
h = {'mare' => 'acqua', 'Eolo' => 'nano', 10 => 'Carla'}
puts h.length
puts h['Eolo']
puts h
puts h[10]Una volta eseguito il nostro piccolo script restituirà i seguenti valori:
3 # il numero delle coppie di indici/valori in hash
nano # la chiave associata al valore "Eolo"
mareacquaEolonano10Carla # tutte le coppie di indici/valori
Carla # valore associato ad un indice numerico interoDa notare come nell’esempio siano stati utilizzati indici di diversa natura, stringhe e interi; per quanto riguarda l’indice intero si noti come esso sia sintatticamente coerente con l’attribuzione di valori numerici alle variabili; perchè rappresenti un numero e non una stringa è infatti necessario che non venga digitato tra apici.
Negli hash troviamo un vantaggio rispetto agli array, è possibile utilizzare indici arbitrari da associare ai valori. Vi è però anche uno svantaggio, gli hash non sono ordinati quindi sono più difficili da utilizzare quando non se ne conosce la composizione interna. Se non conosciamo gli indici sarà infatti difficile poterne richiamare i valori.
Tra l’altro per gli hash è previsto un valore di default, "nil" (ne abbiamo già parlato in precedenza), che viene restituito quando si cerca di accedere a indici non presenti nell’hash:
# chiamata ad indici inesistenti
# definiamo l'hash
h = {'a' => 'b', 'c' => 'd', 'e' => 'f'}
puts h['g'] # stampa "nil"L’esempio proposto stamperà semplicemente "nil", infatti l’indice "g" non è presente nel nostro hash.
In luogo di stringhe e numeri interi, gli hash accettano anche l’utilizzo di simboli per la definizione degli indici:
# hash con simboli come indici
# definiamo l'hash
capoluoghi = Hash.new
capoluoghi[:Lazio] = 'Roma'
capoluoghi[:Campania] = 'Napoli'
capoluoghi[:Sardegna] = 'Cagliari'
puts capoluoghi[:Sardegna] # stampa "Cagliari"Si noti come la definizione dell’hash sia stata effettuata associando al nome dello stesso la chiamata alla classe omonima:
capoluoghi = Hash.newIn Ruby Hash è infatti una classe nativa per la quale il linguaggio mette a disposizione numerosi metodi.
Gestione di file e cartelle con Ruby
Ruby integra strumenti per la creazione, l’apertura, la scrittura, la lettura e la modifica di file e cartelle, il tutto avvalendosi di semplici metodi. Vediamo subito un breve esempio riguardante la creazione di un file e la scrittura all’interno di esso di una riga di testo:
# creazione di un file e scrittura
File.open('file.txt', 'w') do |scrivi|
# inserire il testo tra apici
scrivi.puts 'File creato con Ruby!'
# fine chiamata al metodo
endLo stesso file potrà essere aperto e letto con poche righe di codice:
# apertura e lettura di un file di testo
File.open('file.txt', 'r') do |leggi|
while line = leggi.gets
puts line
# chiusura del ciclo while
end
# fine chiamata al metodo
endSi noti come in questo secondo script abbiamo utilizzato per la prima volta una doppia chiusura ("end" – "end"), grazie ad essa infatti è stato possibile chiudere due differenti blocchi di istruzioni: uno relativo al ciclo "while" per la lettura del file, il secondo relativo alla chiamata del metodo open della classe. I blocchi di istruzione in Ruby possono essere annidati, cioè scritti l’uno all’interno dell’altro.
Tornando all’argomento principale di questo capitolo porremo la nostra attenzione sul metodo utilizzato nei due esempi precedenti. "File.open", metodo relativo alla classe File di Ruby, consente di aprire un file in diversi modalità sulla base di argomenti forniti sotto forma di simboli come per esempio:
- r (read-only, o "sola lettura" ) che apre in lettura ponendo il puntatore all’inizio del file, se non viene specificato alcun argomento dallo sviluppatore esso è considerato dall’interprete come il modo di default
- r+ (read/write, o "lettura e scrittura") che pone il puntatore del file al suo inizio
- w (write-only, o "sola scrittura"), che tronca un file esistente ad una lunghezza zero oppure permette di creare un nuovo file in modalità scrittura
- w+ che apre in lettura e scrittura e pone il puntatore all’inizio del file
- a, che apre in sola scrittura e pone il puntatore alla fine del file
- a+, che apre in lettura e scrittura e pone il puntatore alla fine del file
- b, che apre in modalità binaria (solo per Windows/DOS)
In pratica "File.open" apre un nuovo file se ad esso non corrisponde un blocco associato, il file potrà essere passato come argomento per poi venir chiuso automaticamente nel momento in cui termina il blocco.
I metodi a disposizione per la classe "File" in Ruby sono decine, consigliamo quindi di consultare la manualistica on line per eventuali approfondimenti.
Anche i metodi a disposizione per la gestione delle directory sono molto semplici da utilizzare (classe Dir); innanzitutto abbiamo il metodo pwd che ci permette di sapere il nome e il percorso della directory corrente, per la chiamata a questo metodo basta una semplice istruzione:
# conoscere la directory corrente
Dir.pwdSe invece desideriamo creare una nuova cartella, il metodo di riferimento sarà questa volta mkdir:
# creare una nuova directory
Dir.mkdir('cartella')Naturalmente sarà possibile spostarsi da una cartella all’altra, se per esempio ci trovassimo sulla root di Ruby e volessimo spostarci all’interno della nuova directory creata il metodo da utilizzare sarà chdir:
Dir.chdir('cartella')Per leggere il contenuto di una cartella vi sono vari metodi basati sulla lettura di un vettore attraverso un ciclo. Abbiamo già visto in precedenza il ciclo each – do, quindi per il prossimo esempio proporremo qualcosa di nuovo:
Dir.foreach('cartella') { |file| puts file }foreach vede appunto il contenuto di una cartella (il cui nome è passato come argomento) come un vettore, quando richiamato esso mostrerà tutti i valori per ciascun (foreach) indice presente nel vettore.
Metodi esplici, impliciti e definiti dall’utente in Ruby
Nel corso di questa guida abbiamo sottolineato più volte come Ruby sia un linguaggio orientato agli oggetti; un oggetto ha un nome univo che lo identifica all’interno di un’applicazione, ad esso sono associati dei metodi e questi metodi possono essere di tipo differente.
Vi sono alcuni metodi, come per esempio "puts" e "gets" di cui abbiamo parlato in precedenza, per i quali non sempre facile identificare gli oggetti a cui fanno riferimento. Il metodo "main", anche di questo abbiamo già parlato, è considerato un "metodo implicito" in quanto per decisione dello stesso esecutore fa riferimento a qualsiasi oggetto presente nell’applicazione.
A questo punto è necessario poter utilizzare uno strumento che ci consenta di identificare l’oggetto corrente, cioè quello a cui è associato il metodo che desideriamo utilizzare. Fortunatamente Ruby ci mette a disposizione questo strumento sotto forma di una variabile speciale denominata self; essa potrà essere richiamata attraverso una semplice istruzione:
puts selfNel momento in cui un programma viene eseguito è possibile identificare un solo oggetto accessibile al programma in esecuzione (perchè solo uno "esiste" per l’esecutore); naturalmente, se non è stato richiamato o definito alcun altro metodo, l’esecuzione di "self" restituirà semplicemente "main", il metodo di default.
I metodi nativi in Ruby sono veramente tanti, eppure è possibile anche introdurne di nuovi sulla base delle esigenze dell’utente; vediamo questo semplice esempio:
# definizione di un metodo
# metodo e parametri
def saluto(nome)
# istruzioni
puts 'Buongiorno ' + nome + '!'
# valore di ritorno
return 'Come va?'
# chiusura del blocco di definizione
end
# chiamata al metodo
puts(saluto('Max'))
=begin
La chimata al metodo stampa:
Buongiorno Max!
Come va?
=enddef è l’istruzione che ci permette di definire un metodo; ad essa segue il nome del metodo e tra parentesi i parametri che dovranno essere utilizzati dal metodo; prima della chiusura del blocco sarà possibile indicare le istuzioni che il metodo dovrà compiere e un eventuale valore di ritorno introdotto dal costrutto return. A questo punto, per richiamare il metodo creato sarà sufficiente passargli un valore per il parametro indicato. Chi conosce PHP avrà sicuramente notato come il meccanismo sia molto simile a quello utilizzato nella definizione delle funzioni.
Nella creazione di un metodo l’utente ha la possibilità di definire anche dei valori di default da associare ai parametri argomento del metodo; vediamo un semplice esempio:
=begin
definizione di un metodo
con valori di default
=end
# metodo e parametri
def a(par1='Cane', par2='Gatto', par3='Topo')
#istruzioni
"#{par1}, #{par2} e #{par3}."
# chiusura del blocco di definizione
end
# chiamata al metodo
puts a
# stampa: Cane, Gatto e TopoDa notare l’uso del costrutto "#{parametro}" (operatore di interpolazione) utilizzato per il passaggio delle variabili; quando i parametri sono espressi in questo modo essi devono essere racchiusi tra doppi apici, i singoli apici infatti non "esplodono" le variabili, cioè non ne permettono la stampa del relativo valore (anche qui una similitudine con PHP).
Vediamo ora un secondo esempio:
=begin
definizione di un metodo
senza valori di default
=end
# metodo e parametri
def b(* parametri)
# istruzioni
parametri.each do | vals|
puts vals
# chiusura del blocco di istruzioni
end
# chiusura del blocco di definizione
end
# passaggio di valori al metodo
b('Cane', 'Gatto', 'Topo')
# chiamata al metodo
b()
=begin
la chiamata al metodo stampa:
Cane
Gatto
Topo
=endIn questo secondo caso, i parametri da passare al metodo non sono stati definti a priori i parametri di default da passare al metodo, è stato possibile invece introdurli successivamente (al di fuori del blocco di definizione) grazie all’utilizzo del simbolo "*" che prende il significato di "qualsiasi parametro".
Definizione e uso delle classi in Ruby
Una classe è uno schema per la rapprentazione di un oggetto, la sua esistenza si ispira ad un bisogno di differenziazione della realtà per insiemi e sotto-insiemi. Per fare un esempio potremmo dire che alla classe "animali" fanno riferimento "mammiferi", "rettili" etc.; alla classe "mammiferi" fanno riferimento "felini", "canidi", "pachidermi" etc.; alla classe "felini" fanno riferimento "leoni", "tigri", "gatti" etc.
Ad ogni oggetto corrispondono dei metodi, ciòè le cose che l’oggetto fa, ma anche degli attributi, cioè delle informazioni con cui l’oggetto lavora (ciò che l’oggetto sa).
Nel linguaggio Ruby le classi sono definibili come oggetti di prima classe e ognuno di questi oggetti è un’istanza della classe Class. Nel momento in cui si definisce una nuova classe, utilizzando il costrutto "Nome_classe … end", viene definito e quindi "esiste" un oggetto di tipo "Class" che viene assegnato come valore ad una costante chiamata appunto "Nome_classe".
L’invocazione della classe tramite il costrutto "Nome_classe.new" viene utilizzata per la creazione di un nuovo oggetto; quando ciò accade viene anche eseguito di default il metodo per la nuova istanza della classe che riserva una parte di memoria per l’oggetto creato prima che venga chiamato il metodo per l’inizializzazione dell’oggetto.
Le due fasi descritte ("costruzione" e "inizializzazione" dell’oggetto) avvengono separatamente e possono essere riscritte (overridden); quella relativa all’inizializzazione è determinata dal metodo initialize dell’istanza che non funge da costruttore, compito che spetta invece al metodo new della classe.
Detto questo, per chiarire le idee è possibile riassumere quanto descritto facendo ricorso ad un semplice esempio:
# definizione di una classe in Ruby
# nome della classe
class Friends
# inizializzazione
def initialize(nome1, nome2)
# variabili di istanza della classe
@nome1 = nome1
@nome2 = nome2
# chiusura del blocco d'inizializzazione
end
# definizione di un primo metodo
def saluto
# istruzioni
puts "Ciao #{@nome1}, hai visto #{@nome2}?"
# chiusura del blocco di definizione del primo metodo
end
# definizione di un secondo metodo
def domanda
# istruzioni
puts 'Come sta?'
# chiusura del blocco di definizione del secondo metodo
end
# chiusura del blocco di definizione della classe
end
# costruzione dell'oggetto
d = Friends.new('Carla', 'Luca')
# utilizzo dei metodi
d.saluto # stampa "Ciao Carla, hai visto Luca?"
d.domanda # stampa "Come sta?"Le classi consentono di creare blocchi di istruzioni anche molto lunghi che possono essere salvati in un file e richiamate quando servono tramite una semplice inclusione; per effettuare l’inclusione di un file esterno in Ruby si utilizza l’istruzione require a cui viene passato come argomento il nome del file senza l’estensione ".rb".
Per fare un esempio possiamo includere in un file denominato "class_friends.rb" tutto il codice proposto nel listato precedente fino alla chiusura del blocco di definizione della classe; lo script potrà quindi essere riproposto in questo modo:
# inclusione del file contenente la classe
require 'class_friends'
# costruzione dell'oggetto
d = Friends.new('Carla', 'Luca')
# utilizzo dei metodi
d.saluto # stampa "Ciao Carla, hai visto Luca?"
d.domanda # stampa "Come sta?"In questo modo potremo richiamare la nostra classe in tutti i listati in cui ci può essere utile, senza doverla riscrivere per intero.
Un esempio di RubyGems: Ruby e MySQL
RubyGems è un pratico gestore di packages (librerie) per Ruby che mette a disposizione un formato standard per la distribuzione di programmi e librerie realizzati in Ruby. Questo standard è appunto chiamato gems ed è stato progettato per facilitare la gestione dell’installazione delle librerie e la loro distribuzione.
Installare un nuova "gem" è semplicissimo, basta una connessione ad Internet e il semplice comando gem install seguito dal nome della gemma che si vuole installare; se per esempio volessimo istallare la libreria di Ruby per il DBMS MySQL, dovremmo seguire una procedura come la seguente:
lanciare il comando d’installazione:
C:Ruby> gem install mysql
Bulk updating Gem source index for: http://gems.rubyforge.orgselezionare il pacchetto da installare (meglio la versione più recente perchè è quella che offre il maggior supporto):
Select which gem to install for your platform (i386-mswin32)
1. mysql 2.7.3 (mswin32)
2. mysql 2.7.1 (mswin32)
3. mysql 2.7 (ruby)
4. mysql 2.6 (ruby)
4. Skip this gem
6. Cancel installation
> 1e attendere la risposta da parte del sistema:
Successfully installed mysql-2.7.3-mswin32a questo punto la nuova "gem" sarà installata e funzionante.
Abbiamo mostrato la procedura per Windows, quella per Linux è molto simile; basterà scaricare la tarball desiderata, scompattarla e poi procedere con i comandi:
% ruby ./setup.rb
% ruby ./test.rb host user password
# ruby ./install.rbNaturalmente non sarà possibile interagire con il DBMS fino a quando questo non sarà stato avviato, quindi prima di interfacciarsi a MySQL tramite Ruby bisognerà controllare che il relativo processo sia in esecuzione.
Una volta lanciato il Database server potremo eseguire interrogazioni per MySQL utilizzando i normali comandi SQL; vediamo un semplice esempio:
# connessione a MySQL e query SELECT
# includiamo la classe "mysql"
require 'mysql'
# dati per la connessione al DBMS
# host
# username
# password
# nome del database
con = Mysql.new('localhost', 'usr', 'pass', 'db')
# query di selezione
rs = con.query('select field from tabella')
# ciclo per l'estrazione dei dati
rs.each_hash {|h| puts h['field']}
# chiusura della connessione
con.closeRiassumendo:
- La RubyGem "mysql" ci mette a disposizione una classe omonima per l’interazione con il DBMS che potrà essere richiamata con l’istruzione "require" per le inclusioni
- l’istanza della classe creerà un oggetto che memorizzerà le informazioni relative ai parametri di connessione a MySQL e alla selezione del database
- query è un metodo dell’oggetto creato con l’istanza, permette l’esecuzione del comando SQL (nel nostro caso una SELECT) che le viene passato come argomento al metodo stesso
- il risultato dell’azione del metodo sarà un hash i cui valori potranno essere visualizzati tramite un semplice ciclo
- una volta compiute le operazioni di interrogazione sarà possibile chiudere la connessione al DBMS tramite il metodo close
Probabilmente la "gem" per l’interazione con MySQL ci servirà in più di una occasione, quindi la conserveremo nel nostro sistema; ma nel caso in cui volessimo disinstallarla potremmo farlo con semplice comando valido per tutte le RubyGems:
gem uninstall mysqlL’unico accorgimento da seguire sarà naturalmente quello di modificare a seconda dei casi il nome del parametro (e quindi della "gem") da passare al comando.