Negli ultimi anni la frase “intelligenza artificiale” è ovunque: nei titoli dei giornali, nelle conversazioni in ufficio, nei social, persino nelle pubblicità.
Assistenti vocali che ci rispondono, chatbot che scrivono testi in pochi secondi, automobili che si guidano da sole, software che creano immagini o video dal nulla… sembra magia, ma non lo è.
Dietro l’intelligenza artificiale (IA o AI, dall’inglese Artificial Intelligence) c’è una combinazione straordinaria di matematica, logica e dati, orchestrata per imitare — almeno in parte — alcune capacità umane come imparare, riconoscere, prevedere e decidere.
Ma come siamo arrivati a questo punto? Cosa significa davvero la parola “intelligente” quando parliamo di una macchina? Come può un computer imparare qualcosa da solo? È solo un insieme di algoritmi particolarmente sofisticati, o qualcosa di più profondo?
Dietro queste domande si nasconde un mondo affascinante fatto di statistica, calcolo matematico e design dei modelli, ma anche di intuizione e sperimentazione umana. L’IA non è magia: è un nuovo modo di costruire software che hanno la capacità di adattarsi, migliorare e prendere decisioni sulla base delle informazioni disponibili.
In questo articolo esploreremo come funziona l’intelligenza artificiale, spiegandone i principi chiave in modo chiaro e senza banalizzazioni. Vedremo cos’è l’IA, come fa a “imparare” dai dati e quali tecnologie la rendono possibile — dal machine learning al deep learning. Per i più curiosi e smanettoni cercheremo anche di capire, in estrema sintesi, come è fatto e funziona un modello IA.
Indice
- Cos’è l’intelligenza artificiale
- IA debole e IA forte
- L’intelligenza artificiale non “pensa”: simula l’intelligenza
- Viene superata la logica della programmazione “tradizionale”
- Le principali tecniche usate nell’intelligenza artificiale
- Guardiamo l’IA “sotto il cofano”: come funziona (e si costruisce) un modello intelligente
- Dove viene usata oggi l’intelligenza artificiale
- Limiti e rischi dell’intelligenza artificiale
Cos’è l’intelligenza artificiale
L’intelligenza artificiale è il ramo dell’informatica che studia i sistemi capaci di svolgere compiti che, fino a poco tempo fa, richiedevano l’intervento dell’intelligenza umana.
L’obiettivo dell’AI è far sì che un computer possa analizzare informazioni, riconoscere schemi, prendere decisioni e apprendere dall’esperienza, proprio come farebbe una persona — ma con la velocità e la precisione delle macchine.
Un assistente vocale che comprende la tua richiesta e risponde in linguaggio naturale, un assistente virtuale che suggerisce il film giusto da guardare su Netflix, o un sistema che rileva frodi nelle transazioni online: tutti questi sono esempi di intelligenza artificiale “applicata” a casi concreti.
IA debole e IA forte
Una prima e fondamentale distinzione riguarda i concetti di IA debole e IA forte (in inglese narrow AI e general AI).
- IA debole è quella che conosciamo e utilizziamo oggi. È specializzata in un compito preciso: riconoscere immagini, tradurre testi, generare codice, consigliare prodotti. Funziona molto bene all’interno del suo ambito, ma non “capisce” davvero cosa sta facendo. ChatGPT o Gemini, ad esempio, sono modelli specializzati nella generazione di testi, così come DALL·E e Midjourney lo sono nella creazione di contenuti multimediali.
- IA forte, invece, è (per il momento) un concetto teorico. Si riferisce a una macchina capace di ragionare in modo autonomo e flessibile, comprendendo il mondo come un essere umano. In pratica, sarebbe un sistema in grado di adattarsi a qualsiasi contesto senza bisogno di essere addestrato ogni volta da zero. Al momento, questa forma di IA non esiste: resta un obiettivo di ricerca ancora piuttosto lontano dalla realtà tecnologica attuale.
L’intelligenza artificiale non “pensa”: simula l’intelligenza
Una precisazione importante: il termine “intelligenza artificiale” può trarre in inganno. Sebbene i sistemi di IA eseguano compiti che sembrano “intelligenti”, non possiedono coscienza, emozioni, intenzioni o comprensione del mondo. In altre parole: non capiscono ciò che fanno — ma sanno imitare molto bene il comportamento di chi quelle cose le capisce. La distinzione può sembrare sottile, ma non lo è.
Quando un modello di linguaggio come ChatGPT risponde a una domanda, non “ragiona” nel senso umano del termine. Analizza il contesto della frase, cerca pattern statistici nei dati con cui è stato addestrato e “calcola una risposta” predicendo, via via che elabora il suo output, la parola successiva più probabile. Il risultato è spesso coerente, naturale e sorprendentemente intelligente… ma il processo è puramente matematico e statistico.
Potremmo dire che l’IA non pensa… ma calcola!

Quando parliamo di “intelligenza” artificiale, il termine va interpretato in senso funzionale, non coscienziale. L’IA è “intelligente” perché riproduce comportamenti che, se osservati in un essere umano, considereremmo segno di intelligenza — come riconoscere un volto, tradurre una frase, rispondere a una domanda o produrre un’immagine.
Ma dietro questi risultati non c’è comprensione né intenzione. C’è una rete di modelli matematici che riconosce correlazioni, calcola probabilità e genera output coerenti con ciò che ha appreso dai dati.
Viene superata la logica della programmazione “tradizionale”
Come abbiamo detto l’IA non è intelligente nel senso umano del termine. L’aspetto che distingue l’IA dal software classico è il modo in cui produce risultati.
Un programma tradizionale segue le regole scritte dal programmatore: “se succede A, fai B, altrimenti C”. Un sistema di intelligenza artificiale, invece, non riceve tutte le istruzioni a priori, ma impara dai dati e ciò lo rende capace di compiti più complessi di quelli abitualmente svolti dai software. È questa la vera rivoluzione.
Volendo fare un esempio, è come insegnare a un bambino a riconoscere un gatto: non gli spieghi la definizione di “gatto”, ma gli mostri molti esempi finché impara da solo a distinguere un gatto da un cane. Allo stesso modo, un modello di IA viene addestrato su grandi quantità di dati finché impara a riconoscere schemi e a fare previsioni.
L’idea alla base dell’intelligenza artificiale è semplice ma rivoluzionaria: le macchine possono imparare. Invece di essere programmate per ogni singola situazione, le IA vengono addestrate attraverso i dati (grossi, grossissimi volumi di dati): testi, immagini, numeri, audio, video, ecc. Analizzando i dati, il sistema impara a riconoscere schemi e relazioni e più dati riceve, più diventa preciso e affidabile.
Un esempio concreto: riconoscere un gatto
Tornando all’esempio del bambino, immagina di voler addestrare un sistema informatico per riconoscere i gatti nelle foto. Per farlo non sarebbe possibile scrivere un codice tradizionale con regole del tipo “ha quattro zampe, orecchie a punta e coda pelosa”… perché sarebbe impossibile coprire tutte le varianti!
Per raggiungere l’obiettivo attraverso la IA si procede in modo molto diverso: si predispone un modello di apprendimento e gli si forniscono migliaia (o milioni) di immagini: alcune con gatti, altre senza. Solitamente, almeno all’inizio, chi addestra il modello fornisce già le risposte esatte, in altre parole dice al sistema quali sono foto di gatti e quali no.
Durante l’addestramento, l’IA analizza le foto e cerca correlazioni (pattern) tra i pixel e le risposte fornite (“gatto” / “non gatto”). Ogni volta che sbaglia, corregge i propri pesi interni (i parametri del modello) per migliorare la previsione successiva.
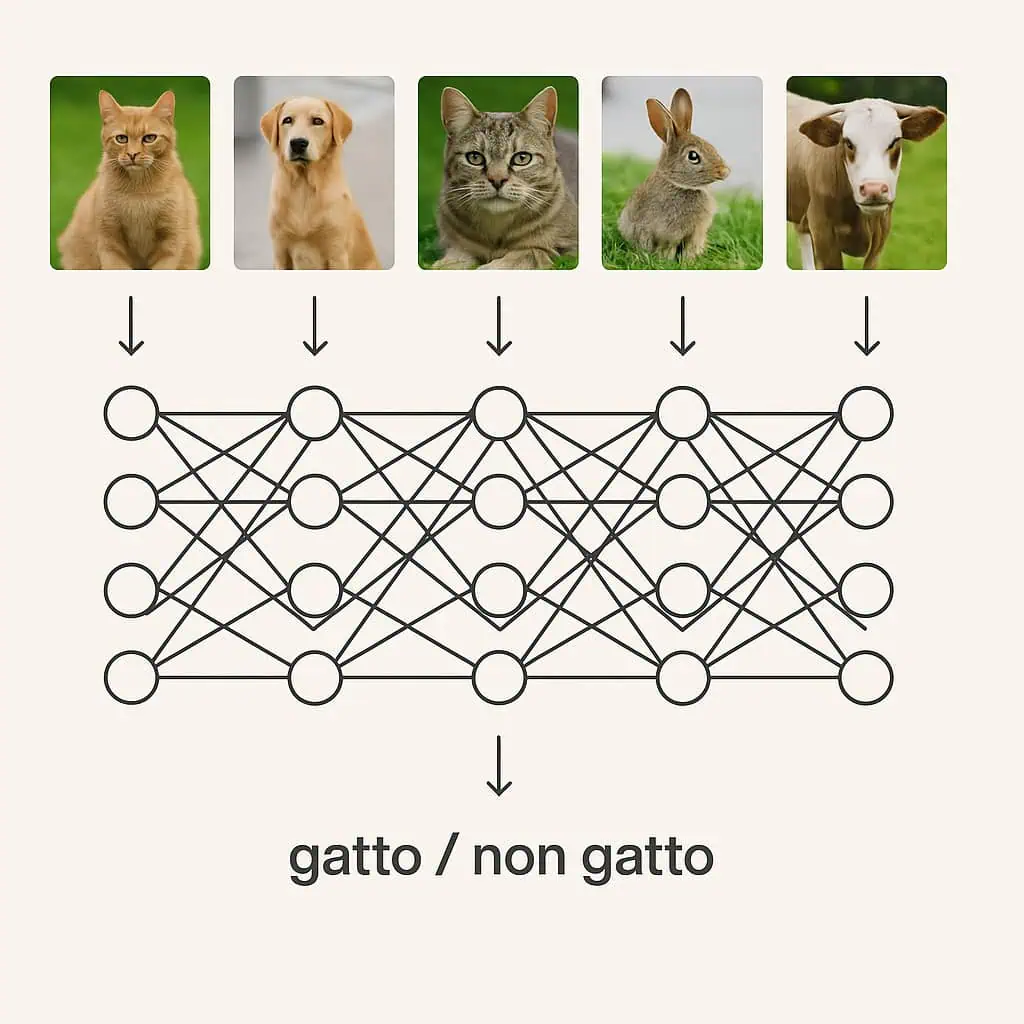
Dopo un certo numero di iterazioni, il sistema impara a riconoscere un gatto anche in immagini mai viste prima. Questo è il cuore dell’intelligenza artificiale: la capacità di generalizzare a partire dai dati.
Dopo l’addestramento, il modello viene testato con nuovi dati (nuove immagini) per verificare quanto è preciso. Se le prestazioni non sono soddisfacenti, si interviene migliorando i dati oppure (se questi sono buoni) cambiando l’architettura o ottimizzando i parametri dell’algoritmo.
Cos’è un “pattern”?
Il termine pattern (in inglese “schema” o “modello ricorrente”) è un concetto molto importante quando si parla di AI. Indica una forma o un comportamento che si ripete nei dati. È una regolarità che il sistema può imparare a riconoscere e utilizzare per fare previsioni o classificazioni.
Nel contesto dell’intelligenza artificiale, un pattern può essere, ad esempio, una combinazione di pixel che identifica le caratteristiche ricorrenti della forma di un gatto all’interno di un’immagine.

Le principali tecniche usate nell’intelligenza artificiale
Dietro ogni sistema di intelligenza artificiale c’è un insieme di tecniche e modelli matematici che consentono alle macchine di estrarre conoscenza dai dati. Non tutte le IA funzionano allo stesso modo, ma la maggior parte delle tecnologie moderne si basa su tre grandi approcci: machine learning, reti neurali artificiali e deep learning.
È bene precisare fin da subito che non sono tecnologie alternative, ma livelli progressivi di complessità all’interno dello stesso ecosistema. Possiamo immaginarli come cerchi concentrici, dove ogni livello successivo include e amplia il precedente, sviluppando sistemi via via più complessi e sofisticati.
Machine Learning
Il machine learning (ML) è la base di quasi tutta l’intelligenza artificiale moderna. Si tratta di un insieme di algoritmi che permettono ai sistemi di riconoscere schemi e prendere decisioni analizzando grandi quantità di dati.
Un modello di machine learning impara attraverso un processo iterativo: analizza i dati, formula ipotesi, verifica gli errori e si corregge da solo. Con il tempo, il sistema diventa più preciso nel risolvere il compito per cui è stato addestrato.
Esempi concreti
- I motori di raccomandazione di Netflix o YouTube, che imparano dai tuoi comportamenti per suggerire film o video simili.
- Gli algoritmi predittivi di Google Ads o Meta Ads, che ottimizzano la distribuzione delle campagne pubblicitarie.
- I filtri antispam di Gmail, che imparano a distinguere le email legittime da quelle indesiderate.
Tre modalità di apprendimento
- Supervisionato – l’IA impara da dati già etichettati (es. “questo è un gatto, questo no”).
- Non supervisionato – l’IA cerca pattern nascosti nei dati senza sapere a priori cosa cercare (utile per il clustering o la segmentazione).
- Premiale o “Per rinforzo” – il modello apprende per tentativi ed errori, premiando i comportamenti “corretti” (es. i sistemi che imparano a giocare a scacchi).
Reti neurali artificiali
Le reti neurali artificiali (ANN) sono un tipo di algoritmo di machine learning ispirato al funzionamento del cervello umano. Qui il discorso si fa più complicato: queste reti sono costituite da “neuroni artificiali” (nodi matematici) organizzati in strati, che comunicano tra loro per elaborare le informazioni.
Ogni neurone riceve input, li elabora attraverso una funzione matematica e trasmette un output agli altri neuroni. Durante l’addestramento, la rete regola automaticamente i “pesi” delle connessioni per ridurre l’errore, migliorando le sue prestazioni.
Esempi concreti
- Il riconoscimento facciale in app come Google Photos o FaceID.
- I sistemi di riconoscimento vocale come Alexa o Siri.
- I modelli di analisi delle immagini mediche, usati per individuare tumori o anomalie in radiografie.
Le reti neurali sono la base di molte applicazioni moderne e quando diventano molto complesse e profonde, si entra nel territorio del deep learning.
Deep Learning
Il deep learning è una branca del machine learning che utilizza reti neurali con molti strati (da cui il termine deep, “profondo”). Questa struttura consente di gestire quantità enormi di dati e di estrarre automaticamente le caratteristiche più rilevanti, senza bisogno di intervento umano.
In pratica, mentre nel machine learning tradizionale l’uomo deve scegliere quali dati o variabili sono importanti, nel deep learning è il modello stesso a “capire” quali pattern contano davvero.
Esempi concreti
- ChatGPT, Claude, Gemini e altri modelli linguistici generativi basati su transformer networks.
- DALL·E, Midjourney o Runway, che generano immagini e video a partire da descrizioni testuali.
- Tesla Autopilot e Waymo, che usano reti neurali profonde per analizzare in tempo reale la scena stradale.
- Google Translate e DeepL, che sfruttano modelli neurali per tradurre testi con precisione sempre maggiore.
Il deep learning è estremamente potente, ma anche molto costoso in termini di calcolo e dati. Richiede GPU, dataset di grandi dimensioni e lunghi tempi di addestramento. In cambio, offre risultati straordinari che fino a qualche anno fa potevano essere contemplati solo dalla fantascienza.
Guardiamo l’IA “sotto il cofano”: come funziona (e si costruisce) un modello intelligente
Per chi, come il sottoscritto, ha un background di programmazione, l’intelligenza artificiale rappresenta l’evoluzione più affascinante e complessa dell’informatica moderna: un insieme di modelli matematici e pipeline di calcolo che creano una incredibile simulazione dell’intelligenza umana.
Non ho la presunzione di capire né tanto meno di spiegare nel dettaglio come funzionino questi sistemi (non sono un data scientist!), ma la curiosità mi ha spinto a sbirciare “sotto il cofano” dell’AI per capire, almeno in piccola parte, quale sia la logica computazionale che rende possibile la risposta di un chatbot o il riconoscimento di un’immagine.
Dati, feature e rappresentazione numerica
Tutto parte dai dati. Che si tratti di testo, immagini o suoni, l’IA lavora sempre su rappresentazioni numeriche — ovvero strutture matematiche come vettori, matrici o tensori (una generalizzazione delle matrici a più dimensioni).
Un’immagine, ad esempio, viene convertita in una matrice di pixel (valori RGB); un testo, invece, viene trasformato in una sequenza di numeri tramite tecniche di embedding, che mappano le parole in uno spazio vettoriale dove termini semanticamente simili risultano “vicini”.
Il compito dell’algoritmo è imparare una funzione di mappatura f(x) che, dato un input numerico x, restituisca un output coerente — come una previsione, una classificazione o una probabilità.
Addestramento, errore e ottimizzazione
Durante la fase di addestramento, il modello riceve dati sotto forma di coppie input–output (“questo è l’esempio, questo è il risultato atteso”).
Ogni volta che il sistema produce una risposta, questa viene confrontata con quella corretta. La differenza tra le due viene misurata attraverso una funzione di perdita (loss function), che quantifica quanto l’output del modello si discosta dal valore desiderato.
L’obiettivo dell’addestramento è minimizzare questa perdita. Per farlo, i parametri interni del modello — i “pesi” delle connessioni tra neuroni artificiali — vengono aggiornati iterativamente tramite algoritmi di ottimizzazione (come Stochastic Gradient Descent o Adam).
In pratica, senza entrare troppo nel dettaglio, il sistema aggiusta i propri parametri per ridurre gradualmente l’errore. Dopo milioni, o addirittura miliardi di iterazioni, il modello “impara” a generalizzare: cioè a produrre buone previsioni anche su dati che non ha mai visto prima.
Architetture e modelli
Le reti neurali moderne si suddividono in diverse architetture, ciascuna progettata per affrontare un tipo di problema specifico:
- CNN (Convolutional Neural Networks) – usate nella visione artificiale. Riconoscono pattern spaziali, forme e strutture nelle immagini grazie a operazioni chiamate “convoluzioni”, che analizzano i pixel in piccoli gruppi (filtri).
- RNN (Recurrent Neural Networks) e LSTM (Long Short-Term Memory) – progettate per analizzare dati sequenziali, come testo o segnali temporali. Mantengono una sorta di “memoria interna” per considerare anche il contesto precedente.
- Transformer – oggi l’architettura dominante per il linguaggio naturale. Si basa su un meccanismo chiamato self-attention, che consente al modello di “prestare attenzione” alle parti più rilevanti di una sequenza, elaborando il contesto in parallelo. È l’approccio su cui si basano modelli come GPT, BERT, Gemini e Claude.
Ogni architettura rappresenta un sofisticato e delicato equilibrio tra complessità, potenza di calcolo e capacità di generalizzazione in ambiti specifici.
La pipeline di sviluppo di un sistema di IA
Dal punto di vista pratico, lo sviluppo di un sistema di IA segue una pipeline (cioè una sequenza di fasi ben definite) abbastanza standard:
- Data Collection – raccolta dei dati grezzi.
- Data Cleaning & Preprocessing – pulizia, normalizzazione e preparazione dei dati (rimozione di valori anomali).
- Feature Engineering – individuazione e creazione delle caratteristiche più rilevanti per il problema da risolvere.
- Model Training – addestramento vero e proprio, spesso eseguito su GPU o cluster distribuiti per gestire grandi quantità di calcolo.
- Evaluation & Validation – valutazione del modello su dati nuovi tramite metriche come accuracy (precisione), recall (capacità di individuare i casi positivi), o F1-score (media bilanciata tra precisione e richiamo).
- Deployment – integrazione del modello in un ambiente di produzione, ad esempio come servizio API o microservizio.
- Monitoring & Retraining – monitoraggio continuo e aggiornamento del modello per gestire il drift (cioè i cambiamenti nel comportamento dei dati nel tempo).
Di seguito uno schema grafico che riassume e semplifica il processo appena descritto:

Alcuni numeri per contestualizzare
Affascinati dal mondo dell’intelligenza artificiale? Avete pensato di sviluppare il vostro modello? Fantastico! Ma prima di perdere qualche notte di sonno davanti alla tastiera, vale la pena dare un’occhiata ai numeri in gioco.
Un moderno modello di deep learning può contenere da decine di milioni a centinaia di miliardi di parametri — ognuno dei quali rappresenta una connessione tra neuroni artificiali, con un proprio peso da ottimizzare.
Addestrare un sistema di queste dimensioni richiede dataset colossali (come ImageNet o Common Crawl), enorme potenza di calcolo su GPU o TPU (processori specializzati per il calcolo parallelo), e spesso giorni o settimane di elaborazione distribuita su centinaia di macchine.
Ecco qualche dato, giusto per farsi un’idea della scala:
- GPT-3 (2020) → circa 175 miliardi di parametri
- GPT-4 (2023) → stime non ufficiali parlano di oltre un trilione di parametri
- CLIP o Stable Diffusion → decine di miliardi di parametri
Una complessità simile giustifica i costi elevatissimi del deep learning: servono centri di calcolo dedicati, gruppi di ricerca multidisciplinari e notevoli risorse energetiche per addestrare e mantenere questi modelli.
Pensare di creare da zero la propria intelligenza artificiale può essere un obiettivo un po’ troppo ambizioso, ma capire come funziona è tutt’altro che inutile: permette di usarla in modo più consapevole, di integrarla in applicazioni e progetti concreti, e magari di sfruttarne il potenziale in contesti più accessibili.
Dove viene usata oggi l’intelligenza artificiale
L’intelligenza artificiale è ormai una tecnologia trasversale: la troviamo integrata in strumenti, piattaforme e processi di quasi ogni settore.
Comunicazione e assistenza virtuale
Gli assistenti vocali come Alexa, Siri e Google Assistant comprendono il linguaggio naturale e rispondono in modo contestuale. I chatbot evoluti, come ChatGPT, Gemini o Claude, vengono utilizzati in assistenza clienti, analisi dei dati, copywriting, formazione aziendale e supporto tecnico.
Nei contact center, l’IA gestisce già migliaia di conversazioni contemporanee, riconoscendo l’intento dell’utente e fornendo risposte personalizzate.
Marketing, dati e personalizzazione
Nel marketing digitale, l’IA è diventata indispensabile. Algoritmi e modelli predittivi ottimizzano targeting, bidding e contenuti, analizzando in tempo reale enormi quantità di dati utente.
Strumenti come Google Ads, Meta Ads, HubSpot e Salesforce Einstein sfruttano reti neurali per segmentare il pubblico, calcolare la probabilità di conversione e personalizzare l’esperienza dell’utente.
In sintesi: l’IA permette ai marketer di passare da una logica “a intuito” a una logica data-driven e predittiva.
Produttività e strumenti di lavoro
Dalle suite d’ufficio ai software di sviluppo, l’IA sta ridefinendo la produttività. Strumenti come Microsoft Copilot, Notion AI o Grammarly assistono nella scrittura, nella generazione di codice o nella creazione di contenuti.
Nel mondo dello sviluppo, GitHub Copilot e Tabnine suggeriscono righe di codice in tempo reale, imparando dallo stile del programmatore.
Per chi lavora nel knowledge work, l’IA non è un sostituto ma un amplificatore cognitivo: accelera i flussi e libera tempo per le attività strategiche.
Medicina e ricerca scientifica
Nel campo medico, l’intelligenza artificiale analizza immagini, referti e dati clinici per supportare diagnosi più rapide e precise. Modelli sviluppati da Google DeepMind, IBM Watson Health e Siemens Healthineers sono in grado di rilevare tumori o anomalie con un livello di accuratezza paragonabile — o talvolta superiore — a quello umano. In farmacologia, sistemi di IA predittiva accelerano la scoperta di nuovi farmaci simulando interazioni molecolari e riducendo tempi e costi di ricerca.
Mobilità, robotica e industria
Le auto a guida autonoma (es. Tesla Autopilot, Waymo, Cruise) utilizzano reti neurali profonde per interpretare la scena stradale, rilevare ostacoli e prendere decisioni istantanee.
Nel settore manifatturiero, algoritmi di manutenzione predittiva anticipano guasti e ottimizzano la produzione. Anche nella logistica, player come Amazon e DHL sfruttano l’IA per gestire rotte, inventari e supply chain globali.
Creatività e contenuti generativi
L’IA non è solo calcolo, ma anche creazione e creatività. Strumenti come DALL·E, Midjourney, Runway o Adobe Firefly generano immagini, video e grafiche da prompt testuali.
Nel mondo della musica, app come AIVA e Suno compongono brani originali; nel cinema e nei videogiochi, l’IA supporta sceneggiatori e designer nella costruzione di ambienti, personaggi e dialoghi.
Vita quotidiana e consumo digitale
L’intelligenza artificiale è anche nei piccoli gesti di ogni giorno:
- nei suggerimenti di film su Netflix o canzoni su Spotify;
- nelle funzioni di correzione automatica di Google Docs;
- nei sistemi di sicurezza biometrica come FaceID;
- o nelle fotocamere degli smartphone, che regolano esposizione e colore in base alla scena.
L’IA è ormai un’infrastruttura invisibile del software moderno. Dalla medicina al marketing, dall’industria creativa alla produttività personale, è il motore che trasforma dati in decisioni, automatizza processi e amplifica le capacità di machine e dispotivi di uso quotidiano nel tentativo di rendere più semplice la vita e il lavoro delle persone.
Limiti e rischi dell’intelligenza artificiale
L’intelligenza artificiale è una tecnologia straordinaria, ma non priva di rischi. Più un sistema diventa autonomo e complesso, più aumentano le sfide legate al controllo, alla trasparenza e all’etica.
Dietro ogni applicazione intelligente esiste infatti una catena di decisioni, dati e assunzioni umane che ne determinano i risultati e, di conseguenza, anche i potenziali errori.
Dati distorti, risultati distorti (il problema del bias)
Ogni modello di intelligenza artificiale “impara” dai dati. Questo significa che se i dati di partenza contengono errori, lacune o distorsioni, l’IA tenderà a riprodurli o persino ad amplificarli.
Nel contesto dell’intelligenza artificiale, si parla di bias quando un algoritmo produce risultati non oggettivi o sbilanciati, non perché “funziona male” ma perché ha “imparato” da dati sbagliati, parziali, incompleti.
È ciò che accade, ad esempio, quando un modello di previsione della domanda di mercato è addestrato su dati incompleti o non aggiornati: i risultati che produce saranno fuorvianti, anche se calcolati con estrema precisione.
Lo stesso vale per un sistema di scoring creditizio che, basandosi solo su certe variabili economiche, penalizza profili che in realtà sono affidabili ma poco rappresentati nel dataset.
Il problema, dunque, non è che l’IA “decida male”, ma che impari male. È bene ricordare, infatti, che un algoritmo è tanto affidabile quanto lo sono i dati su cui viene addestrato.
Mancanza di trasparenza e spiegabilità
Molti modelli di intelligenza artificiale, soprattutto quelli basati su deep learning, sono vere e proprie “scatole nere”, forniscono cioè risultati estremamente accurati, ma è molto difficile comprendere come arrivino a determinate conclusioni.
In ambiti sensibili come la medicina, la finanza o la giustizia, questa opacità è un problema serio:
se un algoritmo suggerisce una diagnosi o rifiuta una richiesta di credito, chi può verificare che la decisione sia corretta, fondata o equa?
Da qui nasce il concetto di Explainable AI (XAI) — un’intelligenza artificiale che non solo sappia fornire un risultato ma che sia anche in grado di spiegare, in modo chiaro, i propri criteri di scelta.
Il rischio, infatti, è che l’uomo — disinteressandosi o non comprendendo i meccanismi che portano al risultato — finisca per accettare in modo fideistico ciò che la macchina produce, rinunciando a esercitare senso critico e controllo (con tutti rischi connessi).
Privacy e uso dei dati
L’IA vive di dati: più ne ha, più è efficace. Ma la raccolta e l’elaborazione di grandi quantità di informazioni personali sollevano questioni cruciali di privacy, sicurezza e governance.
Molte applicazioni — dai modelli linguistici generativi ai sistemi di tracciamento — elaborano testi, immagini, voci e comportamenti online… ma chi controlla questi dati? Per quanto tempo vengono conservati? E, soprattutto, fino a che punto è lecito utilizzarli per addestrare nuovi modelli?
L’Unione Europea, con l’AI Act, sta definendo un quadro normativo volto a garantire maggiore trasparenza, tracciabilità e tutela dei diritti fondamentali. Ma fino a quando non ci sarà piena chiarezza su proprietà, accesso e utilizzo dei dati, questo rimarrà uno dei punti più critici e controversi dell’intelligenza artificiale.
Dipendenza tecnologica e perdita di competenze
Più delegiamo all’IA attività che un tempo richiedevano ragionamento umano, più cresce il rischio di dipendenza cognitiva e tecnologica. Se tutto è automatizzato, cosa resta alla competenza umana?
Quale sarà il ruolo dell’uomo in un contesto dove anche l’intelligenza — il tratto che per millenni ci ha distinto dalle altre specie — viene in parte trasferita alle macchine?
Strumenti come Copilot o ChatGPT possono migliorare la produttività, ma se usati in modo passivo rischiano di indebolire la capacità critica e analitica delle persone.
Per questo motivo l’IA deve essere vista come un amplificatore del pensiero umano, non come un suo sostituto. Solo un utilizzo consapevole di questo strumento permette di conservare il controllo e di trasformare la tecnologia in un reale vantaggio competitivo.
L’impatto sul lavoro e sull’economia
Uno dei temi più discussi riguarda l’impatto dell’intelligenza artificiale sul mondo del lavoro.
Alcune mansioni ripetitive o analitiche potranno essere automatizzate, ma l’IA sta anche creando nuove professioni in ambiti come la data analysis, la progettazione di modelli, la sicurezza informatica e la gestione etica dei sistemi automatizzati.
Il futuro non sarà “senza esseri umani”, ma fatto di collaborazione uomo–macchina.
Le organizzazioni più competitive saranno quelle capaci di integrare le competenze umane — creatività, empatia, giudizio — con la capacità di calcolo e adattamento dell’intelligenza artificiale.
Conclusione
L’intelligenza artificiale non è magia, né un’entità autonoma capace di pensare come un essere umano. È il risultato di decenni di ricerca in ambito matematico, informatico e statistico: un insieme di algoritmi e modelli che simulano alcuni aspetti del ragionamento umano, trasformando enormi quantità di dati in informazioni, decisioni e previsioni.
Oggi l’IA è ovunque: scrive testi, genera immagini, analizza dati, suggerisce strategie e ottimizza processi. Ma, come ogni tecnologia potente, richiede comprensione, controllo e senso critico.
Non possiamo limitarci a utilizzarla: dobbiamo capire come funziona, conoscerne i limiti e mantenerla sotto il governo della razionalità umana, evitando che finisca per indebolire le nostre capacità intellettive e critiche.
Il futuro non sarà dominato dalle macchine, ma costruito da chi saprà collaborare con l’intelligenza artificiale in modo consapevole, sfruttandone il potenziale senza delegare alle macchine la responsabilità delle decisioni.
L’IA non sostituirà l’intelligenza umana, ma la metterà alla prova. Sarà compito delle persone imparare a usare questo strumento in modo intelligente, ricordando che per ottenere buone risposte bisogna prima saper formulare buone domande.